SLIDE 3
- What Should be in the Datapath
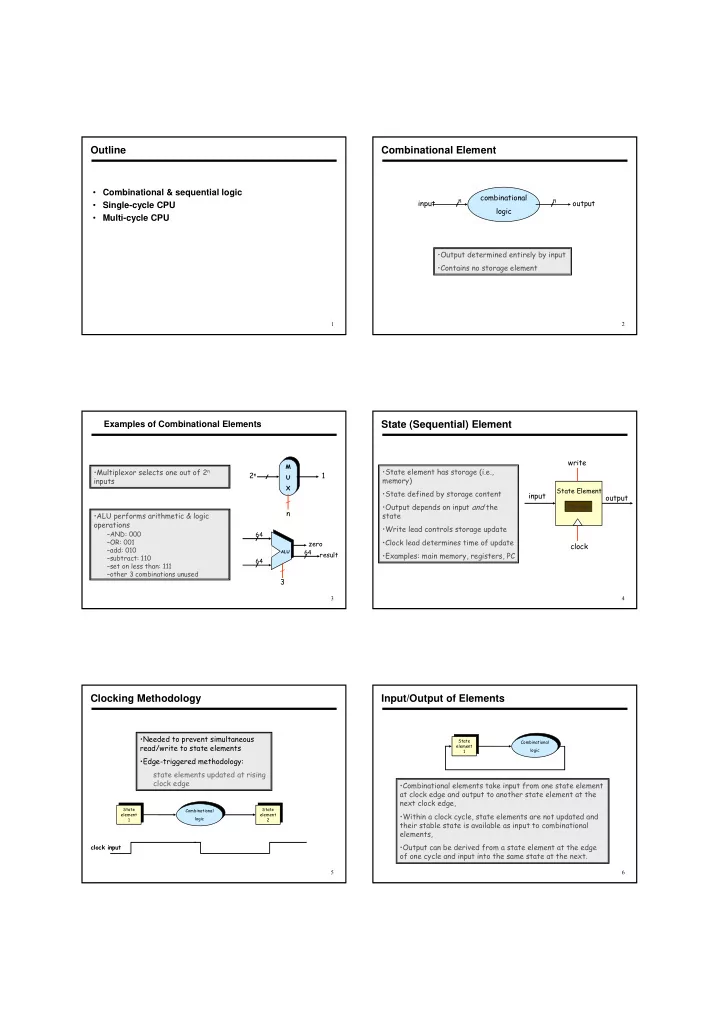
- At a minimum we need combinational and
sequential logic elements in the datapath to support the following functions
– fetch instructions and data from memory – Read registers – decode instructions and dispatch them to the execution unit – execute arithmetic & logic operations – update state elements (registers and memory)
%> %> %>
&
!"" #$%
Datapath Building Blocks: Instruction Access
– a register that points to the next instruction to be fetched – it is incremented each clock cycle
- Content of PC is input to Instruction
Memory
- The instruction is fetched and
supplied to upstream datapath elements
- Adder is used to increment PC by 4 in
preparation for the next instruction (why 4?)
- Adder: an ALU with control input
hardwired to perform add instruction
- nly
- For reasons that will become clear
later, we assume separate memory units for instructions & data
- Datapath Building Blocks: R-Type Instruction
% % 2 2
% 9
%
%2
7 7
)
7 7
%6;9
- Used for arithmetic & logic
- perations
- Read two register, rs and rt
- ALU operates on registers’
content
- Write result to register rd
- Example: add R1, R2, R3
– rs=R2, rt=R3, rd=R1
– RegWrite is asserted to enable write at clock edge – ALUop to control operation
- I-Type Instruction: load/store
- '
7 7 ' :6;
2%0&.%1 *2%706??.%(1 2%0&.%1 *2%706??.%(1
- rs contains the base field for
the displacement address mode
– to load from memory for load – to write to memory for store
- Immediate contains address
- ffset
- To compute memory
address, we must
– sign-extend the 16-bit immediate to 64 bits – add it to the base in rs
– load: registers to read for base address & to write for data – store: registers to read for base address & for data
– to sign-extend and condition immediate field for 2’s complement addition
- f address offset using 64-bit ALU
- ALU
– to add base address and sign-extended immediate field
- Data memory to load/store data:
– memory address; data input for store; data output for load – control inputs: MemRead, MemWrite, clock
Required Datapath Elements for load/store
16