
SLIDE 1
Discrete Random Variables; Expectation 18.05 Spring 2014
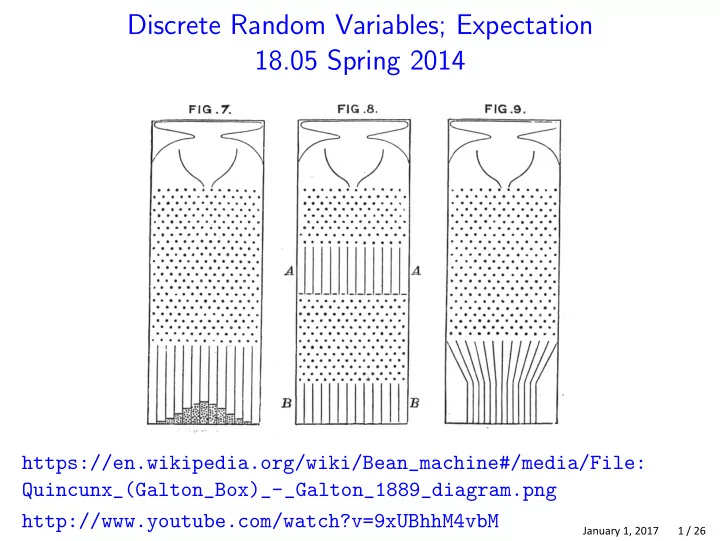
https://en.wikipedia.org/wiki/Bean_machine#/media/File: Quincunx_(Galton_Box)_-_Galton_1889_diagram.png http://www.youtube.com/watch?v=9xUBhhM4vbM
January 1, 2017 1 / 26
Discrete Random Variables; Expectation 18.05 Spring 2014 - - PowerPoint PPT Presentation
Discrete Random Variables; Expectation 18.05 Spring 2014 https://en.wikipedia.org/wiki/Bean_machine#/media/File: Quincunx_(Galton_Box)_-_Galton_1889_diagram.png http://www.youtube.com/watch?v=9xUBhhM4vbM January 1, 2017 1 / 26 Reading Review
January 1, 2017 1 / 26
January 1, 2017 2 / 26
January 1, 2017 3 / 26
January 1, 2017 4 / 26
January 1, 2017 5 / 26
January 1, 2017 6 / 26
January 1, 2017 7 / 26
January 1, 2017 8 / 26
January 1, 2017 9 / 26
January 1, 2017 10 / 26
January 1, 2017 11 / 26
January 1, 2017 12 / 26
January 1, 2017 13 / 26
January 1, 2017 14 / 26
January 1, 2017 15 / 26
January 1, 2017 16 / 26
January 1, 2017 17 / 26
January 1, 2017 18 / 26
January 1, 2017 19 / 26
January 1, 2017 20 / 26
January 1, 2017 21 / 26
January 1, 2017 22 / 26
January 1, 2017 23 / 26
January 1, 2017 24 / 26
January 1, 2017 25 / 26
MIT OpenCourseWare https://ocw.mit.edu
Spring 2014 For information about citing these materials or our Terms of Use, visit: https://ocw.mit.edu/terms.