
SLIDE 1
Maciek Konstantynowicz FD.io CSIT Tech Project Lead FD.io VPP Overview Technology Benchmarking and Performance Facilitating Test Driven Development How to Push Extreme Limits of Performance and Scale with Vector Packet Processing Technology
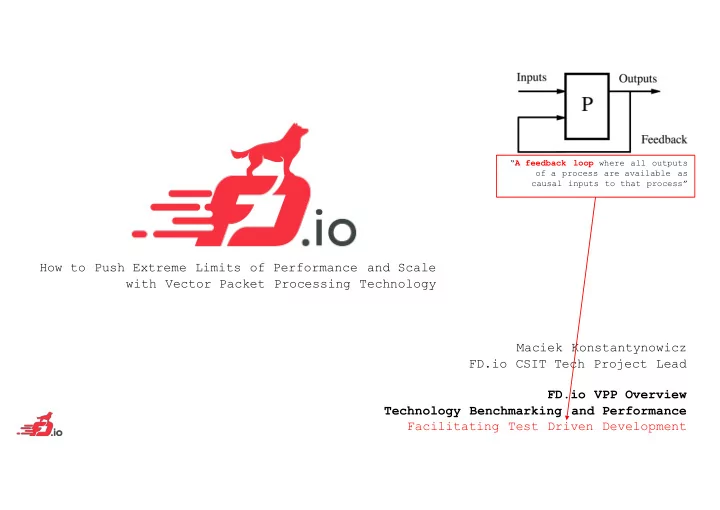
“A feedback loop where all outputs
- f a process are available as
causal inputs to that process”