
SLIDE 1
Recapitulation
What do we want?
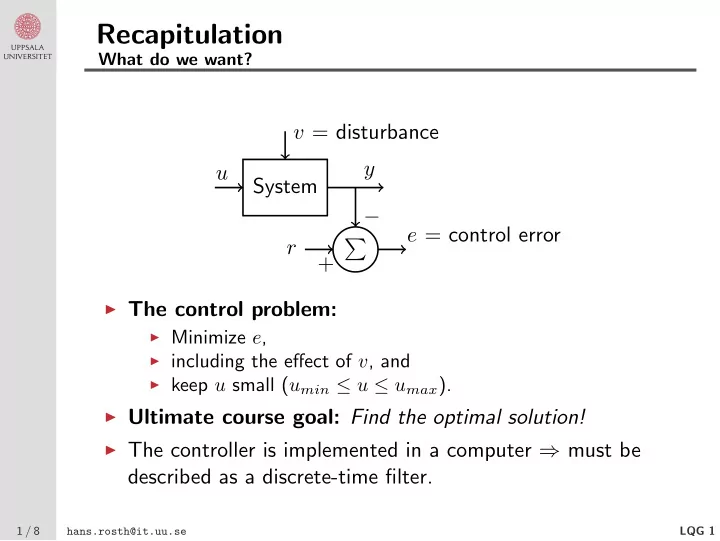
System
- u
y − r + e = control error v = disturbance
◮ The control problem:
◮ Minimize e, ◮ including the effect of v, and ◮ keep u small (umin ≤ u ≤ umax).
◮ Ultimate course goal: Find the optimal solution! ◮ The controller is implemented in a computer ⇒ must be
described as a discrete-time filter.
1 / 8 hans.rosth@it.uu.se LQG 1