
SLIDE 1
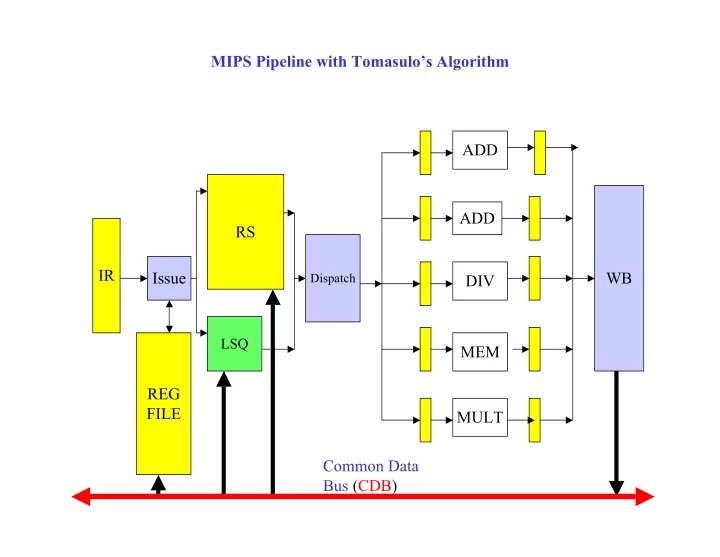
MIPS Pipeline with Tomasulos Algorithm ADD ADD RS IR Issue WB - - PowerPoint PPT Presentation
MIPS Pipeline with Tomasulos Algorithm ADD ADD RS IR Issue WB Dispatch DIV LSQ MEM REG FILE MULT Common Data Bus (CDB) Example LOOP: A LD F0, 0(R1) | temp = x[i] B MUL F4, F0, F2 | temp = temp * a C SD F4, 0(R1) |
2
3
7
C1
MEM
A1
DISPATCH ISSUE WRITE
8
C1 A2 C2
MEM DISPATCH ISSUE WRITE
8
C1 C2
MEM
A2
DISPATCH ISSUE WRITE
8
ADD
MUL
ADD
MUL
4
9
5
W A R
MEM DISPATCH ISSUE WRITE
8
MEM DISPATCH ISSUE WRITE
11
MEM DISPATCH ISSUE WRITE
12
13
14
MEM MEM MEM DISPATCH ISSUE WRITE
15
16
17