SLIDE 1 Something very different
https://nextstrain.org/narratives/ncov/sit-rep/2020-03-04, http://data-science-sequencing.github.io/Win2018/lectures/lecture7/, http://virological.org/t/ response-to-on-the-origin-and-continuing-evolution-of-sars-cov-2/418
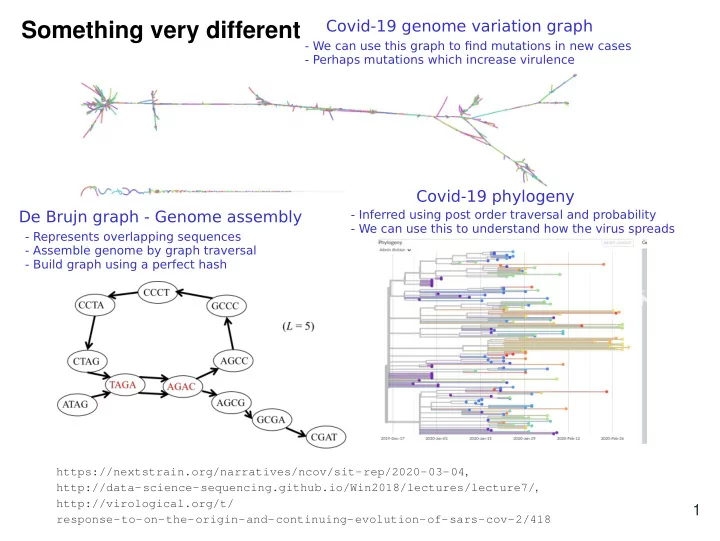
1 Covid-19 genome variation graph Covid-19 phylogeny De Brujn graph - Genome assembly
- Represents overlapping sequences
- Assemble genome by graph traversal
- Build graph using a perfect hash
- Inferred using post order traversal and probability
- We can use this to understand how the virus spreads
- We can use this graph to find mutations in new cases
- Perhaps mutations which increase virulence
SLIDE 2 Back to hashing
((ax +b)modp) modm Warmup: Find the largest set of keys that collide hash(x) = (3x +2)mod9 hash(x) = (3x +2)mod11 Which is a better hash function?
2
1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 9 10
This is bad as we could only map to part of the hash table Any value of the form 11i collides This is better because we map to all values from 0 - 10 The second function is better because 3 is relatively prime to 11 which results in fewer collisions because it avoids degeneracy, that is getting trapped in cycles that don't map to all the possible values. Any value of the form 3i where i is an integer collides Ignoring this for now but p should be bigger than m so we map to all parts of the hash table
SLIDE 3 Hashing with chaining
Store multiple key in each array slot How?
- We will consider linked lists
- Any dictionary ADT could be
used provided ... Result (using linked list)
- We can hash more than m things
into an array of size m
- Worst case runtime depends on
length of largest chain
- Memory is allocated on each
insert
AT GA CT AA TA 1 2 3 4 5 6
3 Keys d["A"] = 1 d["A"] = 2 print d["A"] ? must consider if keys are comparable (ordered) We can store lots of keys but performance degrades We could insert at head or tail of linked list since we need to check if key exists so we must traverse anyways This could lead to bad memory/cache performance hash(AT)=hash(GA)=1
SLIDE 4 Acces time for chaining
Load factor: α = #items hashed #size of array = n m Assuming a uniform hash function i.e. probability of hashing to any slot is equal Search cost:
- Unsuccessful search examines
items
- Successful search examines 1+ n−1
2m = 1+ α 2 − α 2n items
For good performance we want a small load factor
4
α
Hash to a location with an average of
α items
Pay for first item Average # remaining items Our query key is on average 1/2 way through Why do we need this to think about runtime?
SLIDE 5 Open adressing
Each array element contains one item. The hash function specifies a sequence of elements to try. Insert: If first slot is occupied check next location in hash function sequence. Find: If slot does not match keep trying the next slot in sequence until either the item is found or an empty slot is visited (item not found). Remove: Find and replace item with a tombstone. Result:
- Cannot hash more than m items by pigeonhole
principle
- Hash table memory allocated once
- Performance will depend on how many times we
check slots
AT GA CT AA TA 1 2 3 4 5 6
5 GT
GT hash(AT)=hash(GA)=hash(GT)=1 Wrap around using mod m remove(AA)
Clustering
SLIDE 6
Linear probing
Try (h(k)+i) modm for i = 0,1,2,...m −1
2 1 3 4 5 6
For this example h(k) = k mod7 and m = 7
6 insert(76) 76 insert(14) 14 insert(42) 14 76 42 76 insert(83) 14 42 76 83
SLIDE 7
Double hashing
Try (h(k)+i ·h2(k)) modm for i = 0,1,2,...m −1
2 1 3 4 5 6
For this example h(k) = k mod7, h2(k) = 5−k mod 5 and m = 7
7 insert(76) 76 insert(14) 76 14 14 76 insert(42) 42 insert(83) 14 42 76 83 Does not hash to 0!
SLIDE 8 Rehashing
Sometimes we need to resize the hash table
- For open addressing this will have to happen when we fill
the table
- For separate chaining we want to do this when the load
factor gets big To resize we:
- Resize the hash table
- Θ(1) amortized time if doubling
- Get a new hash function
Result:
- Spread the keys out
- Remove tombstones (open addressing)
- Allows arbitrarily large tables
8 One reason we need a new value for mod m since the table size changes Because we have a new hash function
SLIDE 9
Hashing summary
What collision resolution strategy is best? What is the best implementation of a dictionary ADT? Why did we talk about trees?
More in depth info: http://jeffe.cs.illinois.edu/teaching/ algorithms/notes/05-hashing.pdf
9 High load factor: Chaining is better, open addressing suffers from clustering Open addressing can have better memory performance, fewer memory allocations Worst case: Average case: AVL
Θ(log2(n)) Θ(log2(n)) Θ(n) Θ(1)
Hash table Lots of collisions AVL trees can make use of the fact keys are comparable for fast operations:
Θ(log2(n))
Find the max - Keep going right Range queries - Find all values less than a key
SLIDE 10 Something new
What is interesting about this tree?
2 21 5 6 7 8 9 14 15 29 33 42
10
- 1. It is complete - All layers full except
last where all nodes are as far left as possible
- 2. Every node is greater than its
- children. Implies root is min.
Is this a BST?
- No. Does not have search property.
Where should we insert next?