
1
1
Lecture 12: Limits of ILP and Pentium Processors
ILP limits, Study strategy, Results, P-III and Pentium 4 processors
Adapted from UCB CS252 S01
2
Limits to ILP
Conflicting studies of amount
Benchmarks (vectorized Fortran FP vs. integer C programs) Hardware sophistication Compiler sophistication
How much ILP is available using existing mechanisms with increasing HW budgets? Do we need to invent new HW/SW mechanisms to keep on processor performance curve?
Intel MMX, SSE (Streaming SIMD Extensions): 64 bit ints Intel SSE2: 128 bit, including 2 64-bit FP per clock Motorola AltaVec: 128 bit ints and FPs Supersparc Multimedia ops, etc.
3
Limits to ILP
Initial HW Model here; MIPS compilers. Assumptions for ideal/perfect machine to start:
- 1. Register renaming – infinite virtual registers
=> all register WAW & WAR hazards are avoided
- 2. Branch prediction – perfect; no mispredictions
- 3. Jump prediction – all jumps perfectly predicted
2 & 3 => machine with perfect speculation & an unbounded buffer of instructions available
- 4. Memory-address alias analysis – addresses are
known & a load can be moved before a store provided addresses not equal Also: unlimited number of instructions issued/clock cycle; perfect caches; 1 cycle latency for all instructions (FP *,/);
4
Study Strategy
First, observe ILP on the ideal machine using simulation Then, observe how ideal ILP decreases when
- Add branch impact
- Add register impact
- Add memory address alias impact
More restrictions in practice
- Functional unit latency: floating point
- Memory latency: cache hit more than one cycle,
cache miss penalty
5
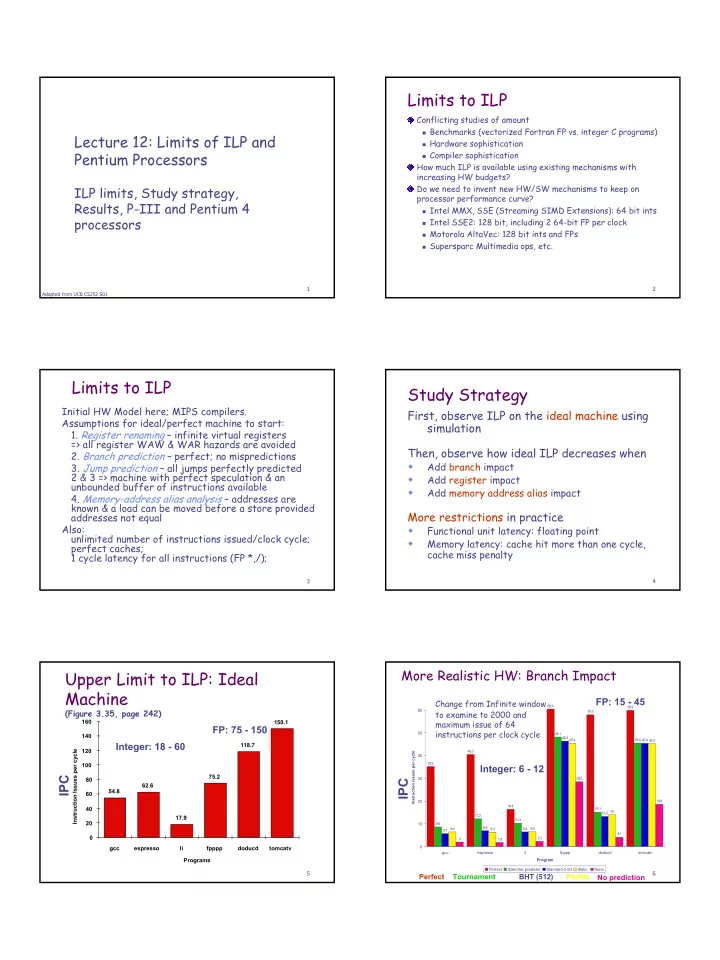
Upper Limit to ILP: Ideal Machine
(Figure 3.35, page 242)
Programs Instruction Issues per cycle 20 40 60 80 100 120 140 160 gcc espresso li fpppp doducd tomcatv 54.8 62.6 17.9 75.2 118.7 150.1
Integer: 18 - 60 FP: 75 - 150
IPC
6
35.2 40.5 16.4 60.9 57.9 59.9 8.6 12.2 10.3 48.1 15.1 5.7 6.9 6.4 46.3 13.2 45.4 6.4 6.3 6.5 45.4 14 45.2 2 1.8 2.3 28.5 4.1 18.6 45.5 10 20 30 40 50 60 gcc espresso li fpppp doducd tomcatv Program Instruction issues per cycle Perfect Selective predictor Standard 2-bit Static None
More Realistic HW: Branch Impact
Change from Infinite window to examine to 2000 and maximum issue of 64 instructions per clock cycle
Profile BHT (512) Tournament Perfect No prediction