
SLIDE 1
Resilient Overlay Networks
CS294-4 Presentation Nikita Borisov Sep 15, 2003
Internet Routing Inefficient
- BGP is designed for scalability, sacrificing
performance
- Link outages common, but routing tables
take minutes to update
- Summarized data creates inefficient paths
- No response to congestion
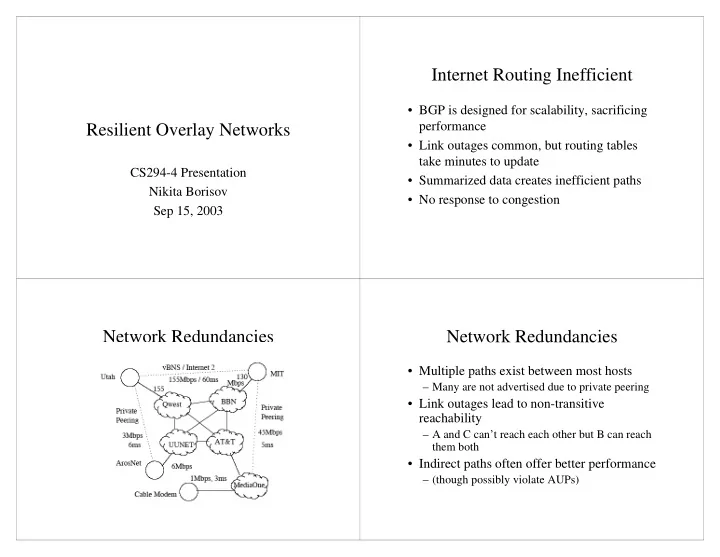
Network Redundancies Network Redundancies
- Multiple paths exist between most hosts
– Many are not advertised due to private peering
- Link outages lead to non-transitive
reachability
– A and C can’t reach each other but B can reach them both
- Indirect paths often offer better performance