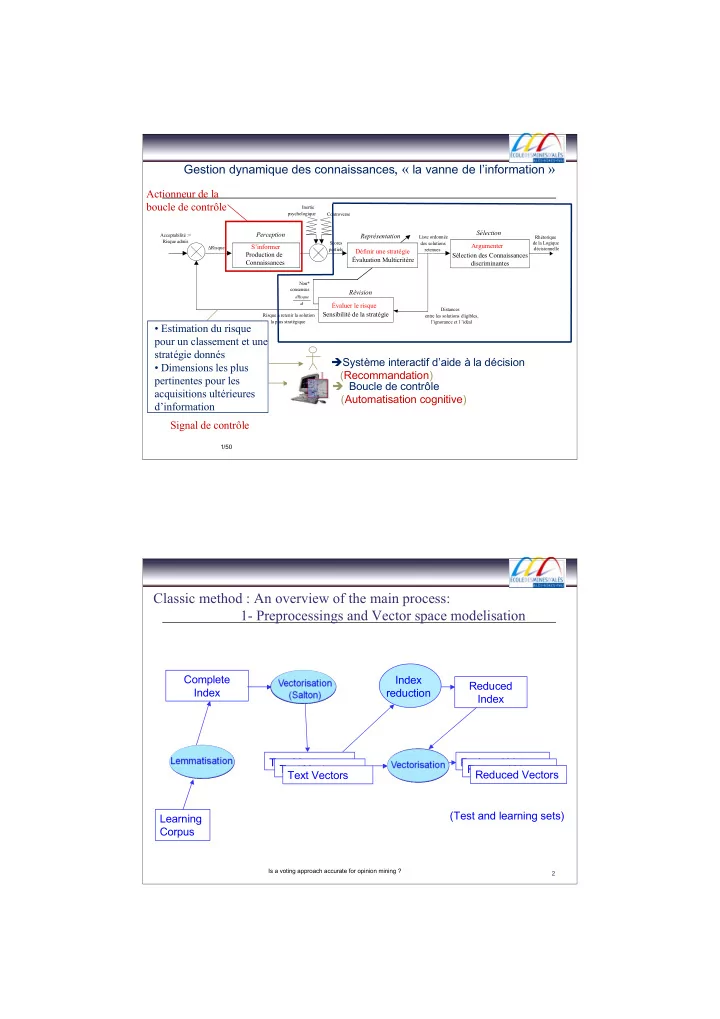

S’informer Production de Connaissances Perception Représentation Évaluer le risque Sensibilité de la stratégie Révision
Liste ordonnée des solutions retenues Rhétorique de la Logique décisionnelle Scores partiels
Définir une stratégie Évaluation Multicritère Argumenter Sélection des Connaissances discriminantes
Distances entre les solutions éligibles, l’ignorance et l ’idéal Risque à retenir la solution la plus stratégique Acceptabilité := Risque admis ∆Risque Inertie psychologique Controverse Non* consensus dRisque dt
Gestion dynamique des connaissances, « la vanne de l’information »
- Estimation du risque
pour un classement et une stratégie donnés
- Dimensions les plus
pertinentes pour les acquisitions ultérieures d’information Actionneur de la boucle de contrôle Système interactif d’aide à la décision (Recommandation) Boucle de contrôle (Automatisation cognitive) Signal de contrôle
Sélection 1/50 Is a voting approach accurate for opinion mining ? 2
Classic method : An overview of the main process: 1- Preprocessings and Vector space modelisation
Learning Corpus Complete Index Reduced Index Index reduction Text Vectors Text Vectors Text Vectors (Test and learning sets) Reduced Vectors Reduced Vectors Reduced Vectors