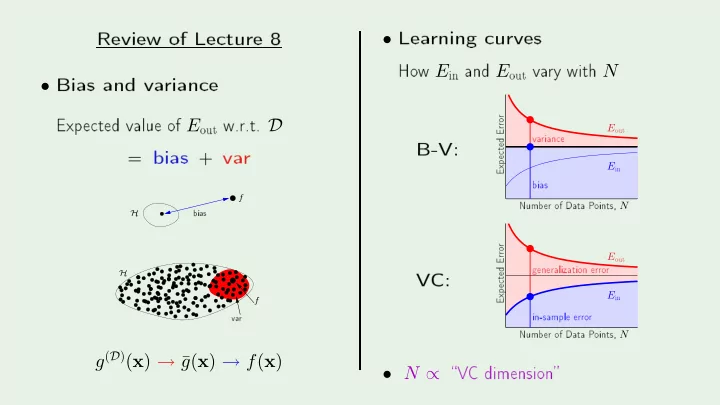

SLIDE 1 Review
- f
- Bias
- f E
- ut
=
bias + va rf H
bias va rf H
g(D)(x) → ¯ g(x) → f(x)
- Lea
- ut
- f
- ints, N
E
- ut
E
in 20 40 60 80 0.16 0.17 0.18 0.19 0.2 0.21 0.22 PSfrag repla ements Numb er- f
- ints, N
E
- ut
E
in 20 40 60 80 0.16 0.17 0.18 0.19 0.2 0.21 0.22- N ∝