
SLIDE 1
Lecture 10
Review
- S. Cheng (OU-Tulsa)
October 17, 2017 1 / 28
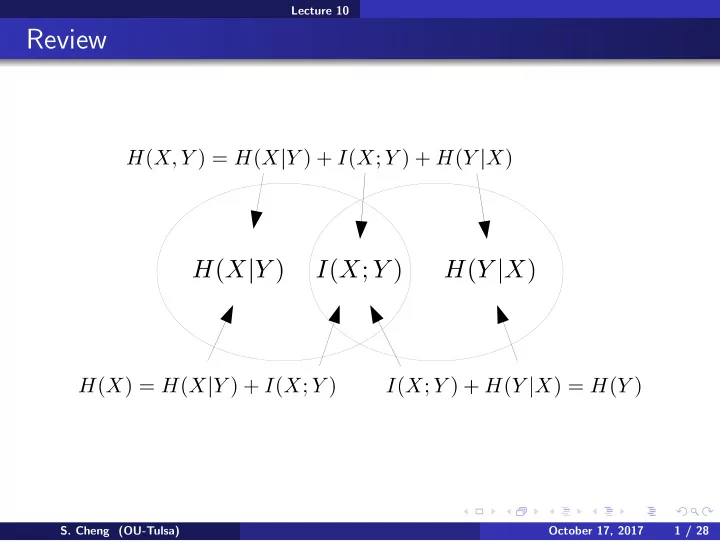
Review S. Cheng (OU-Tulsa) October 17, 2017 1 / 28 Lecture 10 - - PowerPoint PPT Presentation
Lecture 10 Review S. Cheng (OU-Tulsa) October 17, 2017 1 / 28 Lecture 10 Review Conditioning reduces entropy S. Cheng (OU-Tulsa) October 17, 2017 2 / 28 Lecture 10 Review Conditioning reduces entropy Chain rules: H ( X , Y , Z ) S.
Lecture 10
October 17, 2017 1 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10
October 17, 2017 2 / 28
Lecture 10 Overview
October 17, 2017 3 / 28
Lecture 10 Identification/Decision tree
(https://www.youtube.com/watch?v=SXBG3RGr Rc)
October 17, 2017 4 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 5 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 6 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 6 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 6 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 7 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 7 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 8 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 9 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 9 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 9 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 10 / 28
0.2 0.4 0.6 0.8 1 Pr(Head) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Entropy
Lecture 10 Identification/Decision tree
October 17, 2017 10 / 28
0.2 0.4 0.6 0.8 1 Pr(Head) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Entropy
Lecture 10 Identification/Decision tree
October 17, 2017 10 / 28
0.2 0.4 0.6 0.8 1 Pr(Head) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Entropy
Lecture 10 Identification/Decision tree
October 17, 2017 10 / 28
0.2 0.4 0.6 0.8 1 Pr(Head) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Entropy
Lecture 10 Identification/Decision tree
October 17, 2017 10 / 28
0.2 0.4 0.6 0.8 1 Pr(Head) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Entropy
Lecture 10 Identification/Decision tree
October 17, 2017 10 / 28
0.2 0.4 0.6 0.8 1 Pr(Head) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Entropy
Lecture 10 Identification/Decision tree
October 17, 2017 11 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 11 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 11 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 11 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 11 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 12 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 12 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 12 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 12 / 28
Lecture 10 Identification/Decision tree
October 17, 2017 13 / 28
Lecture 10 Law of Large Number
October 17, 2017 14 / 28
Lecture 10 Law of Large Number
October 17, 2017 14 / 28
Lecture 10 Law of Large Number
October 17, 2017 15 / 28
Lecture 10 Law of Large Number
October 17, 2017 15 / 28
Lecture 10 Law of Large Number
October 17, 2017 15 / 28
Lecture 10 Law of Large Number
October 17, 2017 15 / 28
Lecture 10 Law of Large Number
October 17, 2017 16 / 28
Lecture 10 Law of Large Number
October 17, 2017 16 / 28
Lecture 10 Law of Large Number
October 17, 2017 16 / 28
Lecture 10 Law of Large Number
October 17, 2017 16 / 28
Lecture 10 Law of Large Number
October 17, 2017 17 / 28
Lecture 10 Law of Large Number
October 17, 2017 17 / 28
Lecture 10 Law of Large Number
October 17, 2017 17 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 18 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 18 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 18 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 18 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 19 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 19 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 19 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 20 / 28
Lecture 10 Asymptotic equipartition
ǫ (X)
October 17, 2017 20 / 28
Lecture 10 Asymptotic equipartition
ǫ (X)
ǫ (X)
October 17, 2017 20 / 28
Lecture 10 Asymptotic equipartition
ǫ (X)
ǫ (X)
October 17, 2017 20 / 28
Lecture 10 Asymptotic equipartition
ǫ (X)
ǫ (X)
October 17, 2017 20 / 28
Lecture 10 Asymptotic equipartition
ǫ (X)
ǫ (X)
ǫ (X)
ǫ (X)
October 17, 2017 20 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 21 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 22 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 22 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 22 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 22 / 28
Lecture 10 Asymptotic equipartition
October 17, 2017 22 / 28