
SLIDE 1
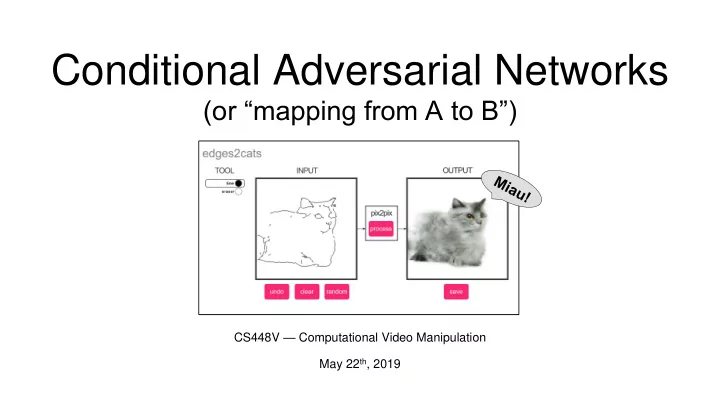
Conditional Adversarial Networks
(or “mapping from A to B”)
CS448V — Computational Video Manipulation May 22th, 2019
Conditional Adversarial Networks (or mapping from A to B) CS448V - - PowerPoint PPT Presentation
Conditional Adversarial Networks (or mapping from A to B) CS448V Computational Video Manipulation May 22 th , 2019 Why? - Cool! Trendy! - Google Scholar Pix2Pix CycleGAN Hundreds of applications and follow-up works Why? -
CS448V — Computational Video Manipulation May 22th, 2019
…
Hundreds of applications and follow-up works
…
CycleGAN Pix2Pix
…
Hundreds of applications and follow-up works
…
CycleGAN Pix2Pix
3 32 width
depth
32
height 32x32x3 image
3 32 width
depth
Convolve the filter with the image, i.e., “slide over the image spatially, computing dot products”
3 5 5
5x5x3 filter
32
height 32x32x3 image
3 32 32
width height depth
Result: 1 number, the result of taking the dot product between the filter and a small 5x5x3 chunk of the image, i.e., 5x5x3 = 70-dimensional dot product + bias
5x5x3 filter wTx + b 32x32x3 image
3 32 32
width height depth
Convolve (slide) over all spatial locations
1 28 28
5x5x3 filter 32x32x3 image Activation map
3 32 32
width height depth
Convolve (slide) over all spatial locations
1 28 28
5x5x3 filter 32x32x3 image Activation map
3 32 32
width height depth
Convolve (slide) over all spatial locations
1 28 28
Invariant to? Translation Rotation Scaling
32x32x3 image Activation map
3 32 32
width height depth
Convolve (slide) over all spatial locations
1 28 28
Invariant to? Translation Rotation Scaling
32x32x3 image Activation map
3 32 32
width height depth
Convolve (slide) over all spatial locations
Activation map 32x32x3 image
3 32 32
width height depth
Convolution Layer
Activation tensor 32x32x3 image
3 32 32
Convolution ReLU e.g. 6 5x5x3 filters
32x32x3 image
3 32 32
Convolution ReLU e.g. 6 5x5x3 filters
6 28 28
32x32x3 image 28x28x6 tensor
3 32 32
Convolution ReLU e.g. 6 5x5x3 filters Convolution ReLU e.g. 10 5x5x6 filters
6 28 28
32x32x3 image 28x28x6 tensor
32x32x3 image
3 32 32
Convolution ReLU e.g. 6 5x5x3 filters Convolution ReLU e.g. 10 5x5x6 filters Convolution ReLU
...
6 28 28 10 24 24
28x28x6 tensor 24x24x10 tensor
[LeNet-5, LeCun 1980]
Learn the features from data instead of hand engineering them! (If enough data is available)
“Propagate low-level features directly, helps with details”
We want to learn 𝑞 X from data, such that we can “sample from it”!
𝑞(X) 𝑞 X
𝐲𝑗 𝑗=1
𝑂
x ~ 𝑞 X
Density Function
New Samples Training Data
“more of the same!”
The world needs more celebrities … or not … ?
𝐲𝑗 𝑗=1
𝑂
x ~ 𝑞 X New Samples Training Data
2018
[Zhang et al., ECCV 2016]
G
Loss Neural Network
[Zhang et al., ECCV 2016]
G
Loss Neural Network
Paired!
[Zhang et al., ECCV 2016]
G
Loss Neural Network
[Zhang et al., ECCV 2016]
G
Neural Network
“What should I do?”
[Zhang et al., ECCV 2016]
G
“How should I do it?”
“What should I do?”
2
2
Deep learning got rid of handcrafted features. Can we also get rid of handcrafting the loss function?
Universal loss function?
Deep learning got rid of handcrafted features. Can we also get rid of handcrafting the loss function?
Universal loss function?
Deep learning got rid of handcrafted features. Can we also get rid of handcrafting the loss function?
Discriminator (Classifier)
Real or Fake?
Generator (G) Input 𝐲 Output 𝐳
Discriminator (D)
Real or Fake?
Generator (G)
G tries to synthesize fake images that fool D D tries to tell real from fake
Input 𝐲 Output 𝐳
Discriminator (D) Generator (G)
Fake (0.9)
D 𝔽𝐲,𝐳[ log D G 𝐲
Input 𝐲 Output 𝐳
“1”
D tries to identify the fakes
Discriminator (D) Generator (G) Discriminator (D)
Fake (0.9) Real (0.1)
D 𝔽𝐲,𝐳[ log D G 𝐲
Input 𝐲 Output 𝐳 GT 𝐳
“1” “0”
D tries to identify the fakes D tries to identify the real images
Discriminator (D) Generator (G)
G 𝔽𝐲,𝐳[ log D G 𝐲
G tries to synthesize fake images that fool D.
Input 𝐲 Output 𝐳
Real (0.1) “0”
Discriminator (D) Generator (G)
G 𝔽𝐲,𝐳[ log D G 𝐲
G tries to synthesize fake images that fool D.
Input 𝐲 Output 𝐳
Real (0.1) “0”
Discriminator (D) Generator (G)
G
D
G tries to synthesize fake images that fool the best D.
Input 𝐲 Output 𝐳
Real or Fake?
Loss Function (D) Generator (G)
G’s perspective: D is a loss function Rather than being hand-designed, it is learned jointly!
Input 𝐲 Output 𝐳
Real or Fake?
Discriminator (D) Generator (G)
G
D
Input 𝐲 Output 𝐳 Input 𝐲
“Rather than penalizing if the output image looks fake, penalize if each overlapping patch in the output looks fake”
Discriminator (D) Generator (G)
Input 𝐲 Output 𝐳
Generator (G)
“Stable training + fast convergence”
100