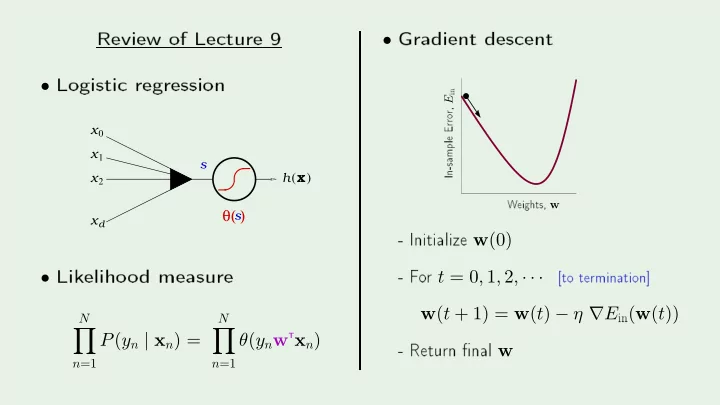

SLIDE 1 Review
- f
- Logisti
s x x x x0
1 2 d
h x
( )
s
θ( )
- Lik
- d
N
- n=1
P(yn | xn) =
N
- n=1
θ(ynw
Txn)- Gradient
- 10
- 8
- 6
- 4
- 2
- Initialize w(0)
- F
- r t = 0, 1, 2, · · ·
w(t + 1) = w(t) − η ∇E
in(w(t))- Return