
SLIDE 1
. .
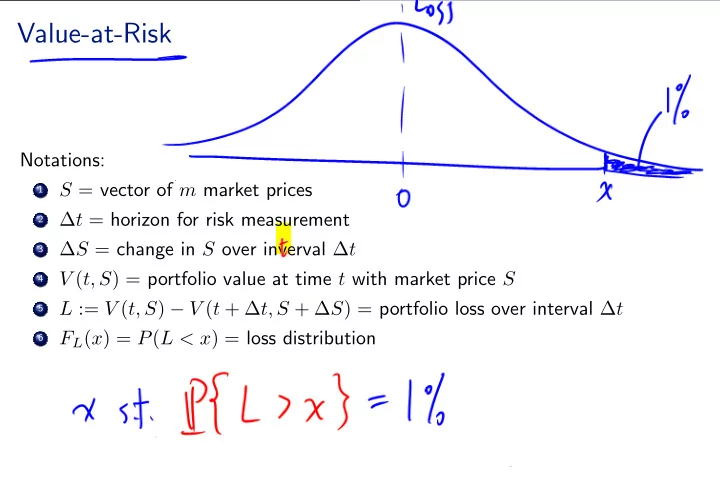
Value-at-Risk
Notations: .
1
S = vector of m market prices .
2
∆t = horizon for risk measurement .
3
∆S = change in S over inverval ∆t .
4
V (t, S) = portfolio value at time t with market price S .
5
L := V (t, S) − V (t + ∆t, S + ∆S) = portfolio loss over interval ∆t .
6