
SLIDE 1
Liang Huang
The City University of New York (CUNY) includes joint work with S. Phayong,
- Y. Guo, and K. Zhao
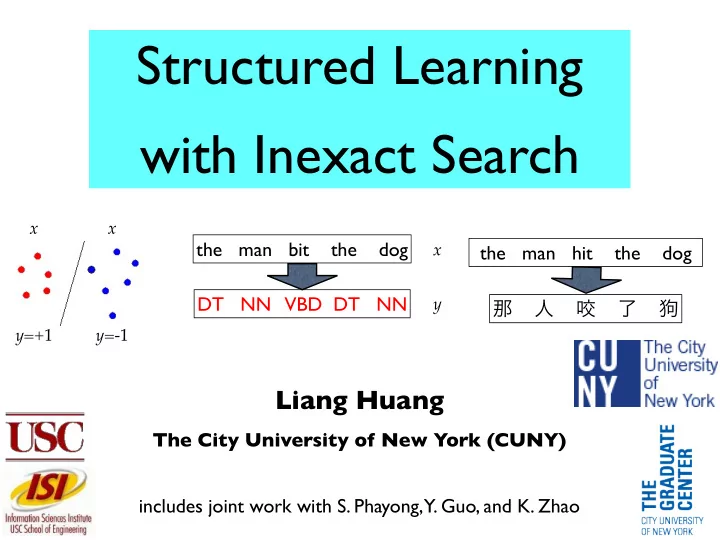
Structured Learning with Inexact Search
the man bit the dog DT NN VBD DT NN
x y x y=-1 y=+1 x
the man hit the dog 那 人 咬 了 狗