
SLIDE 1
Example
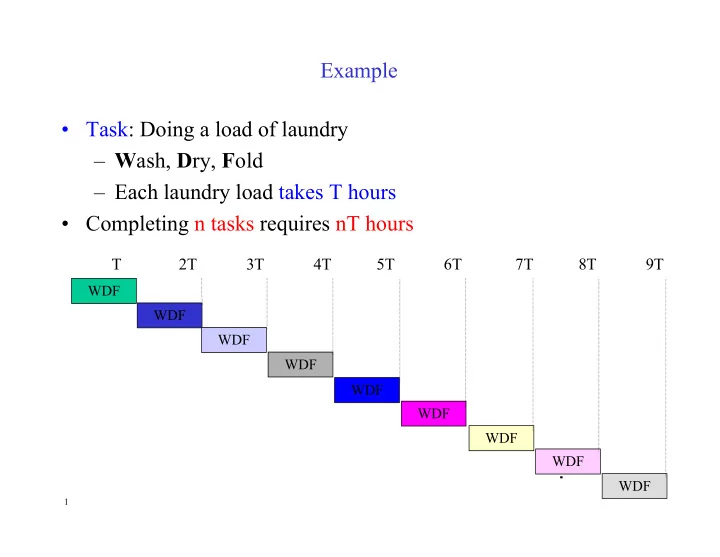
- Task: Doing a load of laundry
– Wash, Dry, Fold – Each laundry load takes T hours
- Completing n tasks requires nT hours
WDF WDF WDF WDF
T 2T 3T 4T 5T 6T 7T 8T 9T
WDF WDF WDF WDF WDF
1