
Maria Hybinette, UGA
1
CSCI: 4500/6500 Programming Languages
Lex & Yacc
Maria Hybinette, UGA
2
Big Picture: Compilation Process
Code Generator Intermediate Code Generator Semantic Analyzer Scanner Lexical Analyzer Parser Syntax Analyzer Computer Symbol Table Lexical units, token stream Parse tree Abstract syntax tree or
- ther intermediate form
Machine Language Optimizer (optional) Source program
Maria Hybinette, UGA
3
Big Picture: Compilation Process
Code Generator Scanner Lexical Analyzer Parser Syntax Analyzer Computer Lexical units, token stream Parse tree Machine Language Source program
Maria Hybinette, UGA
4
Big Picture: Compilation Process
Code Generator Scanner Lexical Analyzer Parser Syntax Analyzer Computer Lexical units, token stream Parse tree Machine/Assembly Language Source program
a = b + c * d id1 = id2 + id3 * id4 = * + id1 id4 id2 id3 load id3 mul id4 add id2 store id1
Maria Hybinette, UGA
5
General Process
! 1975 Lex & YACC automated the compilation process
» The GNU version of these are called flex and bison and are free.
! Lex take patterns and generate code for a lexical analyzer or
scanner.
» Converts strings of input using user defined patterns to tokens.
! Yacc reads user specified grammars to generate code for a
syntax analyzer or a parser, then the parser ‘compiles’ your program in your language
» The syntax analyzer uses grammar rules that allow it to analyze tokens from the lexical analyzer and create a syntax tree (a hierarchical data structure). » CC. ! Final step - code generation, does a depth-first walk of the syntax
tree to generate code (e.g., in machine code).
Maria Hybinette, UGA
6
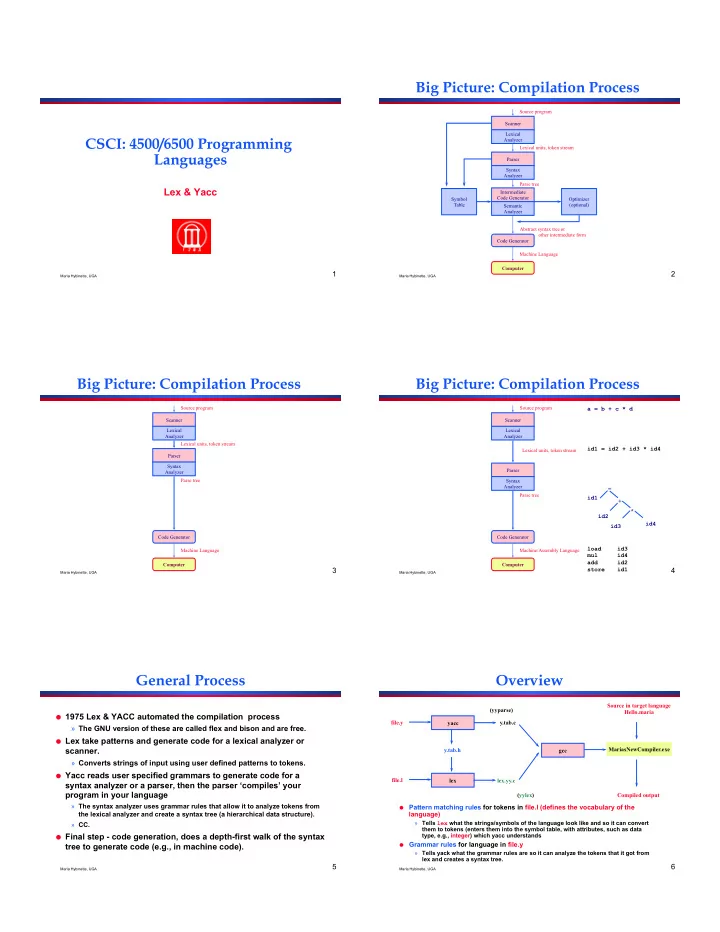
Overview
! Pattern matching rules for tokens in file.l (defines the vocabulary of the
language)
» Tells lex what the strings/symbols of the language look like and so it can convert them to tokens (enters them into the symbol table, with attributes, such as data type, e.g., integer) which yacc understands
! Grammar rules for language in file.y
» Tells yack what the grammar rules are so it can analyze the tokens that it got from lex and creates a syntax tree. (yylex) lex yacc gcc y.tab.h y.tab.c (yyparse) lex.yy.c file.y file.l MariasNewCompiler.exe Source in target language Hello.maria Compiled output