
SLIDE 1
Administrivia
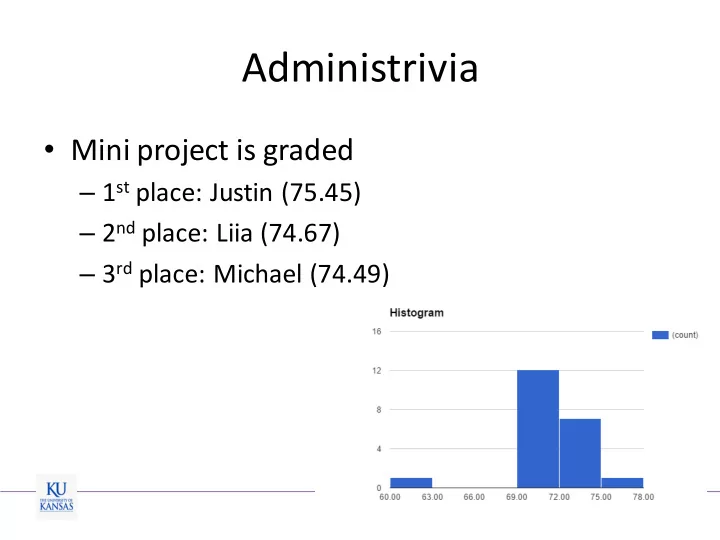
- Mini project is graded
– 1st place: Justin (75.45) – 2nd place: Liia (74.67) – 3rd place: Michael (74.49)
1
Administrivia Mini project is graded 1 st place: Justin (75.45) 2 - - PowerPoint PPT Presentation
Administrivia Mini project is graded 1 st place: Justin (75.45) 2 nd place: Liia (74.67) 3 rd place: Michael (74.49) 1 Administrivia Project proposal due: 2/27 Original research Related to real-time embedded systems/CPS
1
2
3
4
Part 1 Part 2 Part 3 Part 4
5
Core1 Core2 Core3 Core4 DRAM Memory Controller LLC LLC LLC LLC
* Latency – First Access Latency – Further Accesses Data Cycles for each core
Single Core 35 9 4
DDR3 module ACT DATA READ PRE REQUEST #1 ARRIVES close the previous page and load new one Latency of Request #1 REQUEST #1 COMPLETES, REQUEST #2 ARRIVES Latency of Request #2 (with open page) page is already open, just issue read command DATA READ REQUEST #2 COMPLETES
* Latency – First Access Latency – Further Accesses Data Cycles for each core
Single Core 35 9 4 Multiple Cores – same bank/rank 35*N 35*N 4
A D R P A D R P A D R P
ALL REQUESTS ARRIVE AT THE SAME TIME, TARGETED AT SAME BANK AND RANK
* Latency – First Access Latency – Further Accesses Data Cycles used by each access
Single Core 35 9 4 N Cores – same bank/rank 35 + 35*(N-1) 35 + 35*(N-1) 4 N Cores – different ranks 35 + 4*(N-1) 9 + 4*(N-1) 4 ACT DATA R PRE ALL REQUESTS ARRIVE AT THE SAME TIME, TARGETED AT DIFFERENT RANKS DATA DATA ACT R PRE ACT R PRE
9
10
11
– Less than peak b/w – How much?
L3 DRAM DIMM Memory Controller (MC) Bank 4 Bank 3 Bank 2 Bank 1
Core1 Core2 Core3 Core4
13
14
15
16
17
18
19
20
Image source: [Wilhelm et al., 2008]
21
22
23
24
[11]–[13]. control-flo flo first first
program’ flo control-flo identifies
processor’ finally control-flo ely—together interactions—to influence influence influence
25
26
Image source: [Wilhelm et al., 2008]
27
Image source: [Wilhelm et al., 2008]
28
29
30
FETCH DECOD E REGACC MEM EXECUT E EXCEPT FETCH DECOD E REGACC MEM EXECUT E EXCEPT FETCH DECOD E REGACC MEM EXECUT E EXCEPT FETCH DECOD E REGACC MEM EXECUT E EXCEPT FETCH DECOD E REGACC MEM EXECUT E EXCEPT FETCH DECOD E REGACC MEM EXECUT E EXCEPT FETCH DECOD E REGACC MEM EXECUT E EXCEPT FETCH DECOD E REGACC MEM EXECUT E FETCH DECOD E REGACC MEM FETCH DECOD E REGACC FETCH DECOD E FETCH
t
THREAD#1 THREAD#2 THREAD#3 THREAD#4 THREAD#5 THREAD#6
1 clock Thread 1, Instruction 1 Thread 1, Instruction 2
31
32
33
34
35