
SLIDE 1
30‐Mar‐15 1
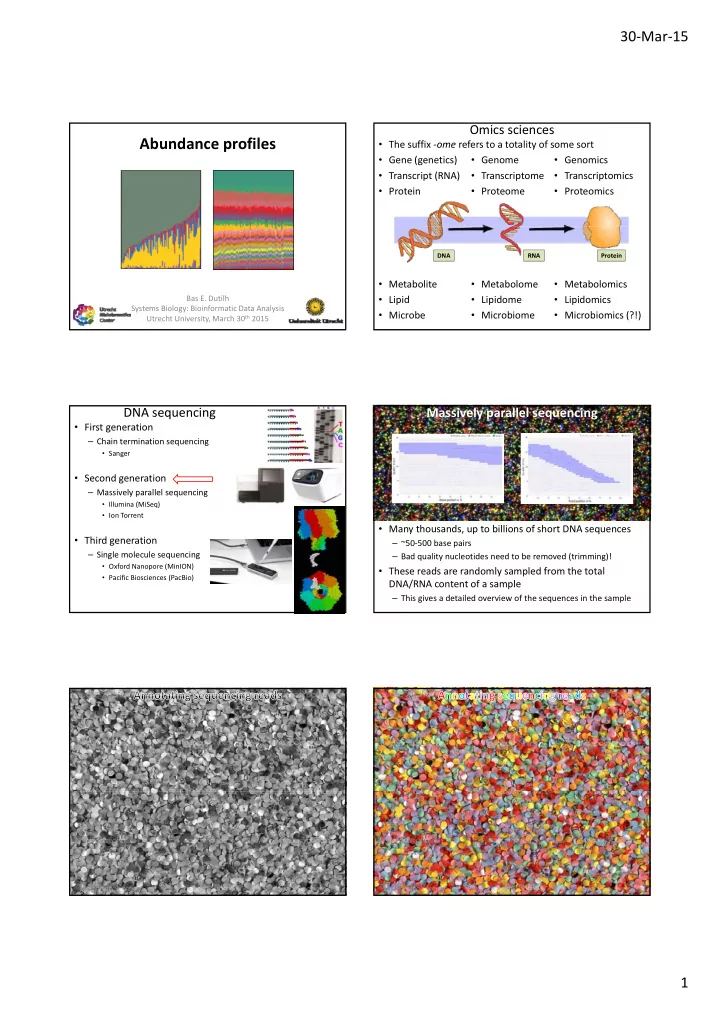
Abundance profiles
Bas E. Dutilh Systems Biology: Bioinformatic Data Analysis Utrecht University, March 30th 2015
Omics sciences
- The suffix ‐ome refers to a totality of some sort
- Gene (genetics)
- Transcript (RNA)
- Protein
- Genome
- Transcriptome
- Proteome
- Genomics
- Transcriptomics
- Proteomics
RNA Protein
- Metabolite
- Lipid
- Microbe
- Metabolome
- Lipidome
- Microbiome
- Metabolomics
- Lipidomics
- Microbiomics (?!)
DNA
DNA sequencing
- First generation
– Chain termination sequencing
- Sanger
- Second generation
– Massively parallel sequencing
- Illumina (MiSeq)
- Ion Torrent
- Third generation
– Single molecule sequencing
- Oxford Nanopore (MinION)
- Pacific Biosciences (PacBio)
Massively parallel sequencing
- Many thousands, up to billions of short DNA sequences
– ~50‐500 base pairs – Bad quality nucleotides need to be removed (trimming)!
- These reads are randomly sampled from the total