SLIDE 8 8
Silberschatz, Galvin and Gagne 2002 6.29 Operating System Concepts
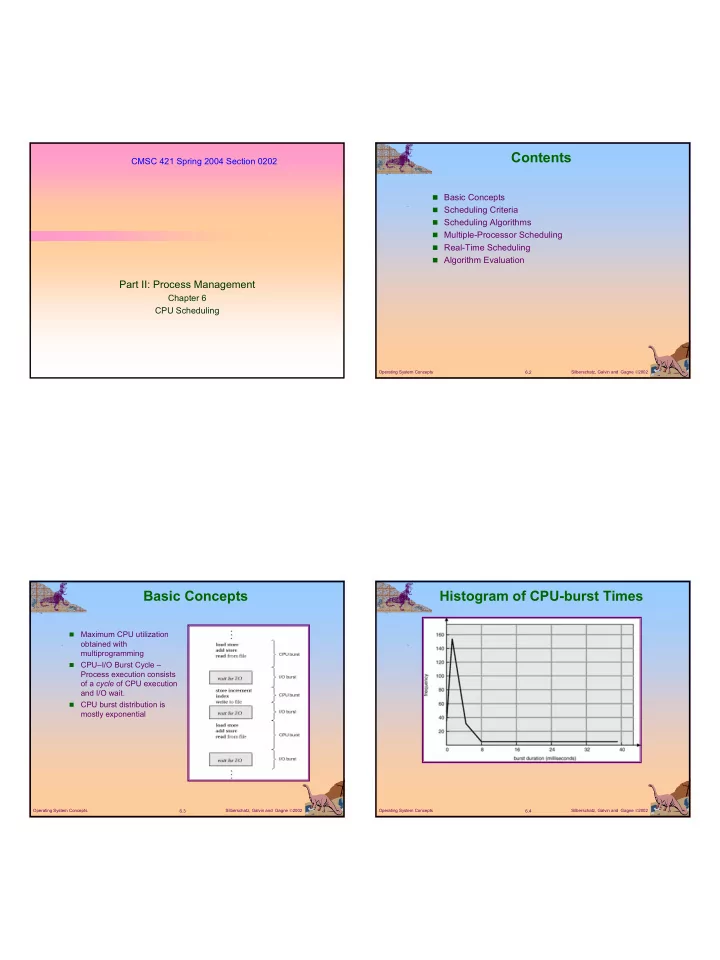
Multilevel Feedback Queues
Silberschatz, Galvin and Gagne 2002 6.30 Operating System Concepts
Example of Multilevel Feedback Queue
Three queues
Q0 – time quantum 8 milliseconds Q1 – time quantum 16 milliseconds Q2 – FCFS
Scheduling
A new job enters queue Q0 which is served FCFS. When it
gains CPU, job receives 8 milliseconds. If it does not finish in 8 milliseconds, job is moved to queue Q1.
At Q1 job is again served FCFS and receives 16 additional
- milliseconds. If it still does not complete, it is preempted
and moved to queue Q2.
Silberschatz, Galvin and Gagne 2002 6.31 Operating System Concepts
Multiple-Processor Scheduling
- CPU scheduling is more complex when multiple CPUs are
available.
All processors are identical within the multiprocessor system
Idle processors share the load of busy processors Maintain a single ready queue shared among all the processors
- Symmetric multiprocessing
Each processor schedules a process autonomously from the
shared ready queue
- Asymmetric multiprocessing
- nly one processor accesses the system data structures, alleviating
the need for data sharing.
Could lead to I/O bottleneck on one processor
Silberschatz, Galvin and Gagne 2002 6.32 Operating System Concepts
Real-Time Scheduling
When it is required to complete a critical task within a guaranteed
amount of time
Resource reservation
No strict guarantee on the amount of time When it is required that critical processes receive priority over less
fortunate ones.
- For soft real-time scheduling
System must have priority scheduling The dispatch latency must be small Problem caused by the fact that many OSs wait for a context
switch until either a system call completes or an I/O blocks