
SLIDE 1
What is Statistical Learning?
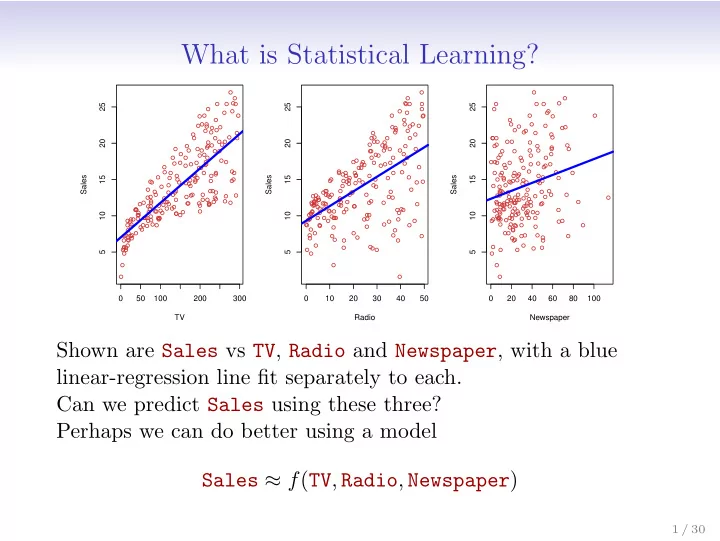
50 100 200 300 5 10 15 20 25 TV Sales 10 20 30 40 50 5 10 15 20 25 Radio Sales 20 40 60 80 100 5 10 15 20 25 Newspaper Sales
Shown are Sales vs TV, Radio and Newspaper, with a blue linear-regression line fit separately to each. Can we predict Sales using these three? Perhaps we can do better using a model Sales ≈ f(TV, Radio, Newspaper)
1 / 30