
SLIDE 1
Vectors, matrices, eigenvalues and eigenvectors
1
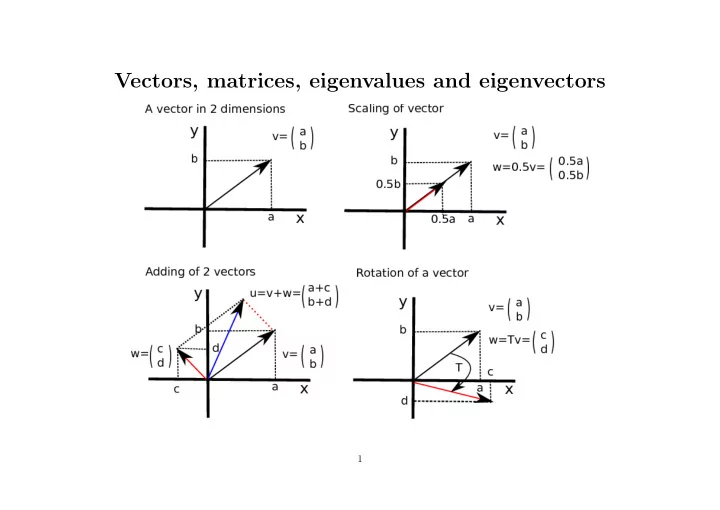
Vectors, matrices, eigenvalues and eigenvectors 1 1 2 0 . 5 2 - - PowerPoint PPT Presentation
Vectors, matrices, eigenvalues and eigenvectors 1 1 2 0 . 5 2 Scaling a vector: 0 . 5 V = 0 . 5 = = 1 0 . 5 1 0 . 5 2 1 2 + 1 3 Adding two vectors: V + W = + = =
1
3
4
5
6
7
8
9
10
400 600 800 1000 1200 0.0 0.2 0.4 0.6 0.8 1.0 Time in years Frequency
Blackgum Red maple Beech
(a) 5 10 15 5 10 15 x y
(2,1) (4,5) (14,13) (b)
11
12
13
14
15
18
20
21
23
24
25
28
29
30
32
34
36
38
x y
(x,y)
x y
(x,y) (x+h,y) (x,y+h)
x y
(x,y)
39
42
43
45
46
48
49
complex number z
real part imaginary part
50
51
52
with λ1,2 = tr ±
and
54
55
56
(a) R dN/dt 0.5 1 1 (b) t hR, hN 10 20
0.05 (c) t x(t), y(t) 10 20
0.05
57
x(t) y(t)) = e−0.25t [C1v1(cos 0.43t + i sin 0.43t) + C2v2(cos 0.43t − i sin 0.43t)]
59