
SLIDE 1
Not Every Pattern Is Interesting!
- Trivial patterns
– Pregnant à Female 100% confidence
- Misleading patterns
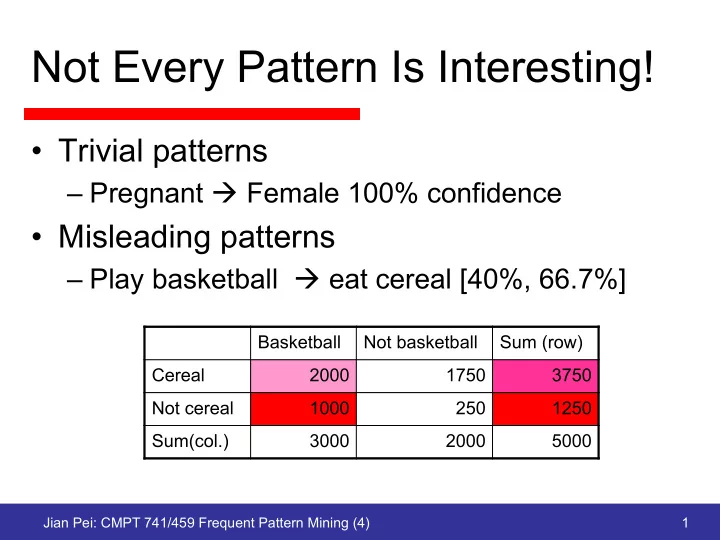
– Play basketball à eat cereal [40%, 66.7%]
Jian Pei: CMPT 741/459 Frequent Pattern Mining (4) 1
Basketball Not basketball Sum (row) Cereal 2000 1750 3750 Not cereal 1000 250 1250 Sum(col.) 3000 2000 5000