
SLIDE 1
Neural-Symbolic Integration Strategies
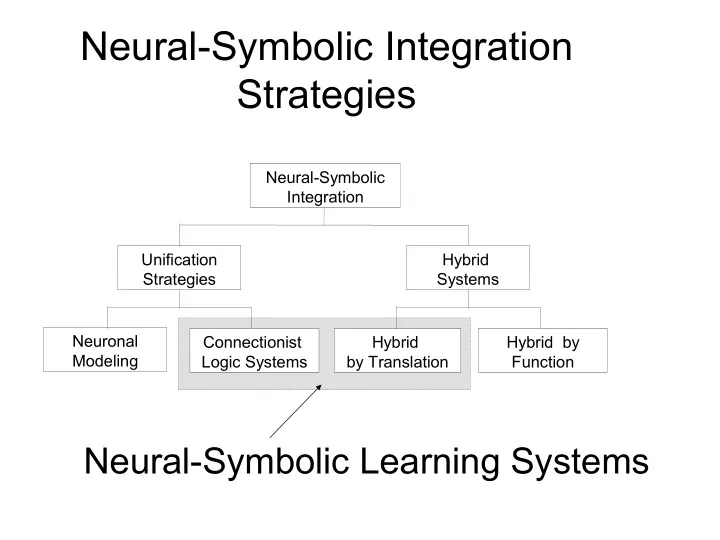
Neuronal Modeling Connectionist Logic Systems Hybrid by Translation Hybrid by Function Hybrid Systems Unification Strategies Neural-Symbolic Integration
Neural-Symbolic Integration Strategies Neural-Symbolic Integration - - PowerPoint PPT Presentation
Neural-Symbolic Integration Strategies Neural-Symbolic Integration Unification Hybrid Strategies Systems Neuronal Connectionist Hybrid Hybrid by Modeling Logic Systems by Translation Function Neural-Symbolic Learning Systems CILP:
Neuronal Modeling Connectionist Logic Systems Hybrid by Translation Hybrid by Function Hybrid Systems Unification Strategies Neural-Symbolic Integration
C ← F, ~G; F ← A ← B,C,~D; A ← E,F; B ←
Symbolic Knowledge Symbolic Knowledge Neural Network Examples
Learning Connectionist System
Inference Machine
Explanation
1 3 2 4 5
Inserting Background Knowledge Performing Inductive Learning with
Adding Classical Negation Adding Metalevel Priorities Experimental Results
A B
θ A θ B
W W W
θ 1 N 1 θ 2 N2 θ 3 N 3
B F E D C W W W
W
Int er pr etatio ns
Wr = 1 A B
W W W W W N1 N3 N2 (1+A min )W (1+A min )W/2 W W W
T F E D C B Interpretations 1
W > 2 (ln(1+Amin) – ln(1-Amin)) / (max(k,m).(Amin-1)+Amin+1)
Θh = (1+Amin).(k-1).W/2 (threshold of hidden neuron) ΘA = (1+Amin).(1-m).W/2 (threshold of output neuron) Amin > max(k,m)-1 / max(k,m)+1 Amax = -Amin (for simplicity)
We add extra input, output and hidden
We fully-connect the network We use Backpropagation
B
¬ C
B
¬ C
D A
¬ E
N1 N3 N2 W W W
W W W
N1 W
W
W W W N2 A B ¬B C B ¬D A N3
a x r2 r1 b c d e ¬x
W
r1 r2 r3 guilty ¬ guilty fingertips alibi super-grass
r1 r2 r3 guilty ¬ guilty fingertips alibi super-grass
r1 r2 r3 guilty ¬ guilty fingertips alibi super-grass
r1 r2 r3 r4
X ¬X
Test Set Performance (how well it
Test Set Performance over small/increasing
Training Set Performance (how fast it trains)
♦ A short DNA sequence that preceeds the beginning of
genes.
Background Knowledge
Promoter ← Contact, Conformation Contact ← Minus10, Minus35 Minus 10
← @ -14 ‘tataat’
Minus 10
← @ -13 ‘ta’, @ -10 ‘a’, @ -8 ‘t’
Minus 10
← @ -13 ‘tataat’
Minus 10
← @ -12 ‘ta’, @ -7 ‘t’
Minus 35
← @ -37 ‘cttgac’
Minus 35
← @ -36 ‘ttgac’
Minus 35
← @ -36 ‘ttgaca’
Minus 35
← @ -36 ‘ttg’, @ -32 ‘ca’
Conformation
← @ -45 ‘aa’, @ -41 ‘a’
Conformation ← @ -45 ‘a’, @ -41 ‘a’, @ -28 ‘tt’, @ -23 ‘t’, @ -21 ‘aa’, @ -17 ‘t’, @ -15 ‘t’, @ -4 ‘t’ Conformation ← @ -49 ‘a’, @ -44 ‘t’, @ -27 ‘t’, @ -22 ‘a’, @ -18 ‘t’, @ -16 ‘tg’, @ -1 ‘a’ Conformation ← @ -47 ‘caa’, @-43 ‘tt’, @-40 ‘ac’, @-22 ‘g’, @-18 ‘t’, @-16 ‘c’, @-8 ‘gcgcc’, @-2 ‘cc’
a
a g t c a g t c a g t c
Minus35 Minus10 Conform. Contact Promoter
+7 Minus35 Minus10 Conform. Contact
94.3 94.3 91.5 80.2 93.4 97.2 10 20 30 40 50 60 70 80 90 100 Storm
P erceptron Cobweb Backprop C-IL2P Test Set P erform ance
97.2 92.5 86.8 85.8 79.0 98.1 10 20 30 40 50 60 70 80 90 100 E ither FOCL Labyrinth KBANN C-IL2P KBCNN Test Set P erformance
0.1 0.2 0.3 0.4 0.5 0.6 20 40 60 80
N u m b e r o f T r a i n i n B a c k p K B A N C
2 P
0.1 0.2 0.3 0.4 0.5 0.6 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 Training Epochs RMS Error Rate Backprop KBANN C-IL2P
♦ Points on a DNA sequence at which the cell removes superfluous
DNA during the process of protein creation. DNA Intron Exon Intron Exon Intron mRNA Exon Exon Background Knowledge
EI ← @ -3 ‘aaggtaagt’, ~EI
EI ← @ -3 ‘caggtaagt’, ~EI
EI ← @ -3 ‘aaggtgagt’, ~EI
EI ← @ -3 ‘caggtgagt’, ~EI
EI-Stop ← @ -3 ‘taa’ EI-Stop ← @ -4 ‘taa’ EI-Stop ← @ -5 ‘taa’ EI-Stop ← @ -3 ‘tag’ EI-Stop ← @ -4 ‘tag’ EI-Stop ← @ -5 ‘tag’ EI-Stop ← @ -3 ‘tga’ EI-Stop ← @ -4 ‘tga’ EI-Stop ← @ -5 ‘tga’ IE ← @ -3 ‘tagg’, Piramidal, ~IE
IE ← @ -3 ‘cagg’, Piramidal, ~IE
Piramidal ← @ -15 ‘tttttttttt’ Piramidal ← @ -15 ‘cccccccccc’ IE-Stop ← @ 1 ‘taa’ IE-Stop ← @ 2 ‘taa’ IE-Stop ← @ 3 ‘taa’ IE-Stop ← @ 1 ‘tag’ IE-Stop ← @ 2 ‘tag’ IE-Stop ← @ 3 ‘tag’ IE-Stop ← @ 1 ‘tga’ IE-Stop ← @ 2 ‘tga’ IE-Stop ← @ 3 ‘tga’
Piramidal EI-Stop IE-Stop EI IE
DNA +30 Piramidal EI-St IE-St
89.7 89.2 88.0 93.5 94.8 10 20 30 40 50 60 70 80 90 100 ID3 P erceptron Cobweb Backprop C-IL2P Test Set P erform ance
90.2 94.8 10 20 30 40 50 60 70 80 90 100 KBANN C-IL2P Test Set P erformance
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8
100 200 300
Number of Training Examples
Test Set Error Rate %
B a c k p K B A N C
2 P
0.1 0.2 0.3 0.4 0.5 0.6 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Training Epochs RMS Error Rate Back prop KBANN C-IL2P
CILP's test set performance is comparable
CILP's test set performance in the
CILP's training set performance is superior
CILP uses Backpropagation CILP uses Background Knowledge CILP's translation of BK into N is compact
The combination of theory and data
Single hidden layer neural networks
Preference relations can be encoded