SLIDE 8 hablar hablo hablas habla hablamos hablan habl´ e hable hables hablar
ar
s r ∅ r mos r n ar ´ e ar e ar es
hablo
e
hablas
s r as
∅ s mos s n as ´ e as e as es
habla
∅ r a
s ∅ mos ∅ n a ´ e a e a es
hablamos
mos r amos
s mos ∅ mos n amos ´ e amos e amos es
hablan
n r an
s n ∅ n mos an ´ e an e an es
habl´ e
´ e ar ´ e
e as ´ e a ´ e amos ´ e an ´ e e ´ e es
hable
e ar e
as e a e amos e an e ´ e ∅ s
hables
es ar es
as es a es amos es an es ´ e s ∅
buscar busco buscas busca buscamos buscan busqu´ e busque busques buscar
ar
s r ∅ r mos r n car qu´ e car que car ques
busco
co qu´ e co que co ques
buscas
s r as
∅ s mos s n cas qu´ e cas que cas ques
busca
∅ r a
s ∅ mos ∅ n ca qu´ e ca que ca ques
buscamos
mos r amos
s mos ∅ mos n camos qu´ e camos que camos ques
buscan
n r an
s n ∅ n mos can qu´ e can que can ques
busqu´ e
qu´ e car qu´ e co qu´ e cas qu´ e ca qu´ e camos qu´ e can ´ e e ´ e es
busque
que car que co que cas que ca que camos que can e ´ e ∅ s
busques
ques car ques co ques cas ques ca ques camos ques can es ´ e s ∅
hables hables hables hables hables hables hables hables hables hables
qu c qu c qu c
hables
qu c qu c qu c
hables
qu c qu c qu c
hables
qu c qu c qu c
hables
qu c qu c qu c
hables
qu c qu c qu c
hables
c qu c qu c qu c qu c qu c qu
hables
c qu c qu c qu c qu c qu c qu
hables
c qu c qu c qu c qu c qu c qu
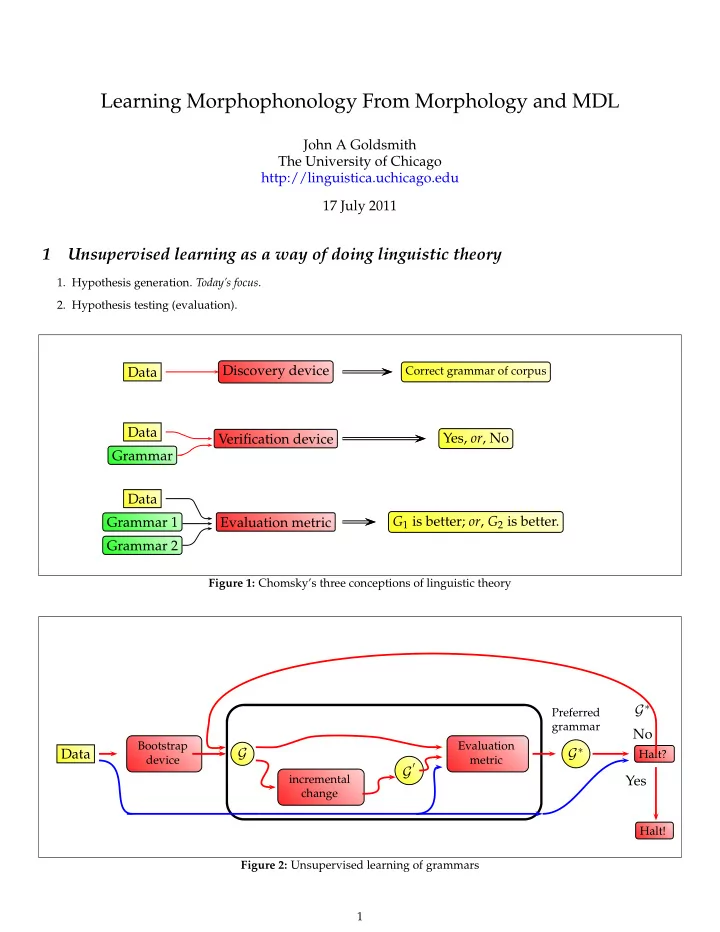
Figure 10: Difference of differences: Spanish verb 8