
SLIDE 1
1
(c) 2003 Thomas G. Dietterich 1
Entropy
- Let X be a discrete random variable
- The surprise of observing X = x is defined
as
– log2 P(X=x)
- Surprise of probability 1 is zero.
- Surprise of probability 0 is ∞
(c) 2003 Thomas G. Dietterich 2
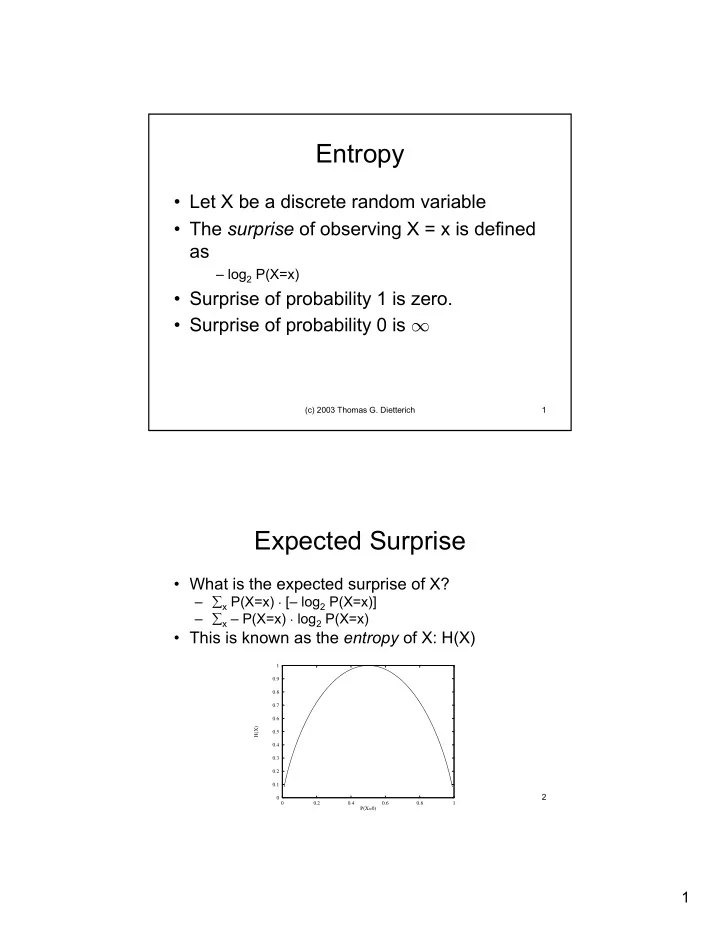
Expected Surprise
- What is the expected surprise of X?
– ∑x P(X=x) · [– log2 P(X=x)] – ∑x – P(X=x) · log2 P(X=x)
- This is known as the entropy of X: H(X)
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.2 0.4 0.6 0.8 1 H(X) P(X=0)