
SLIDE 1
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 1/8
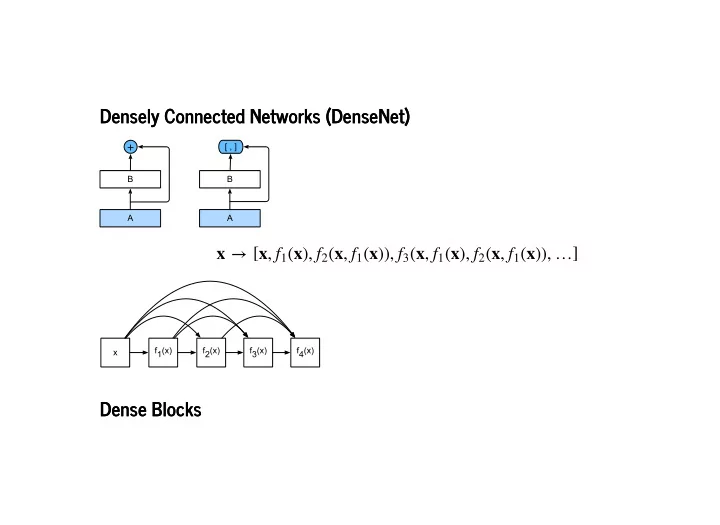
Densely Connected Networks (DenseNet) Densely Connected Networks - - PowerPoint PPT Presentation
3/8/2019 densenet slides Densely Connected Networks (DenseNet) Densely Connected Networks (DenseNet) x [ x , ( x )), ] f 1 ( x ), f 2 ( x , f 1 ( x )), f 3 ( x , f 1 ( x ), f 2 ( x , f 1 Dense Blocks Dense Blocks
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 1/8
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 2/8
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 3/8
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 4/8
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 5/8
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 6/8
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 7/8
3/8/2019 densenet slides http://127.0.0.1:8000/densenet.slides.html?print-pdf/#/ 8/8