
SLIDE 1
Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 4 Instance-Based Learning Introduction to Data Mining , 2nd Edition
by Tan, Steinbach, Karpatne, Kumar
9/30/2020 Introduction to Data Mining, 2nd Edition 2
Data Mining Classification: Alternative Techniques Lecture Notes - - PDF document
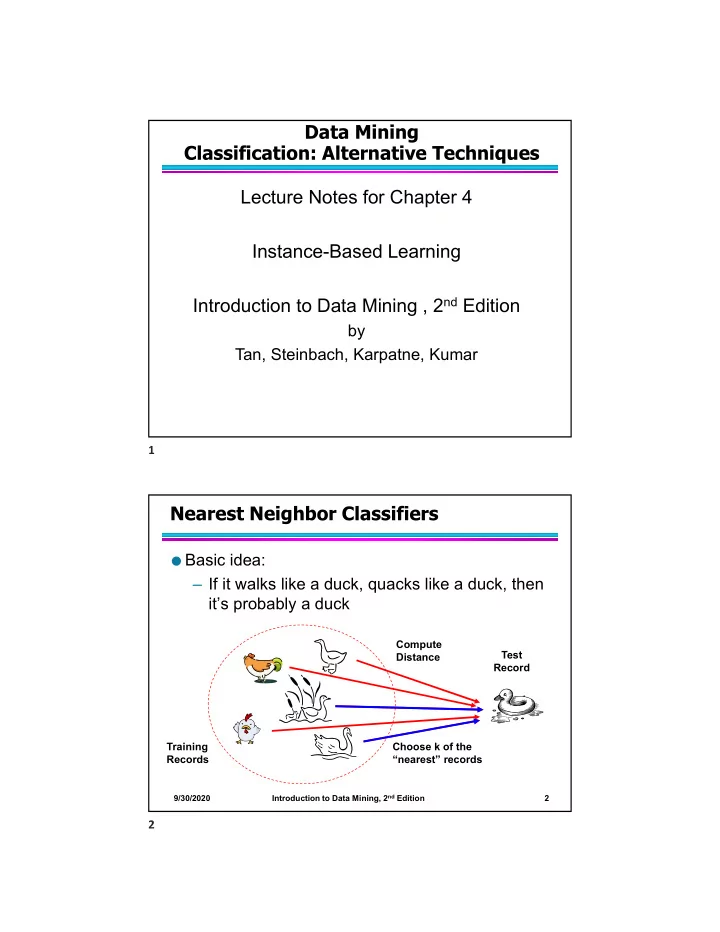
Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 4 Instance-Based Learning Introduction to Data Mining , 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 1 Nearest Neighbor Classifiers Basic idea: If it
9/30/2020 Introduction to Data Mining, 2nd Edition 2
9/30/2020 Introduction to Data Mining, 2nd Edition 3
Unknown record 9/30/2020 Introduction to Data Mining, 2nd Edition 4
9/30/2020 Introduction to Data Mining, 2nd Edition 5
9/30/2020 Introduction to Data Mining, 2nd Edition 6
9/30/2020 Introduction to Data Mining, 2nd Edition 7
Example:
9/30/2020 Introduction to Data Mining, 2nd Edition 8
9/30/2020 Introduction to Data Mining, 2nd Edition 9
9/30/2020 Introduction to Data Mining, 2nd Edition 10
9/30/2020 Introduction to Data Mining, 2nd Edition 11