
SLIDE 1
CSCE 970 Lecture 4: Nonlinear Classifiers
Stephen D. Scott
January 29, 2001
1
Introduction
- For non-linearly separable classes, performance
- f even the best linear classifier might not be
good
- Thus we will remap feature vectors to new
space where they are (almost) linearly sepa- rable
- Outline:
– Multiple layers of neurons ∗ Backpropagation ∗ Sizing the network – Polynomial remapping – Gaussian remapping (radial basis functions) – Efficiency issues (support vector machines) – Other nonlinear classifiers (decision trees)
2
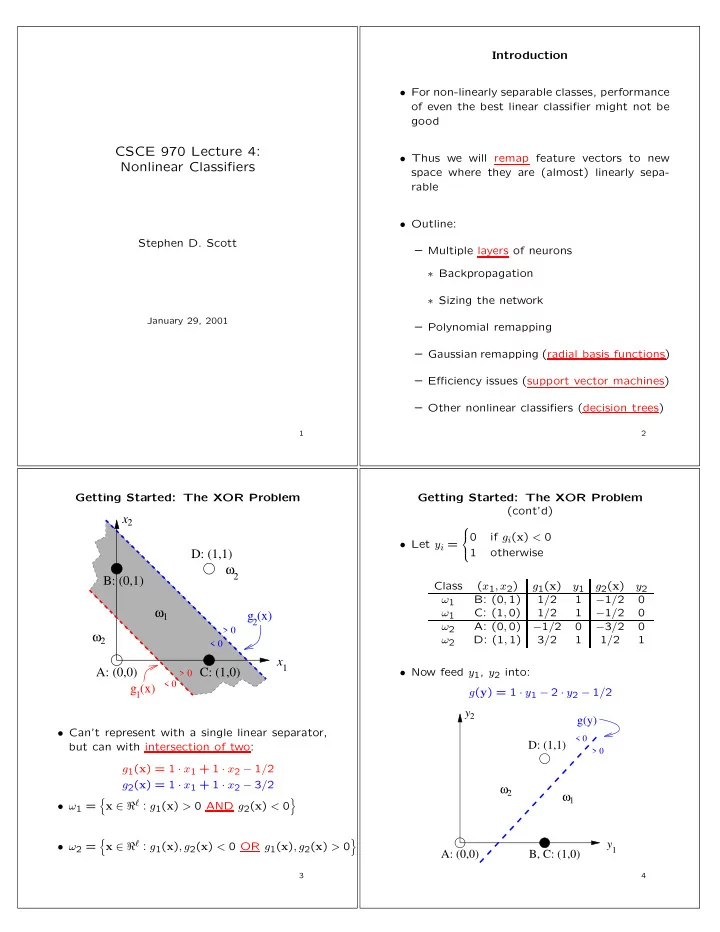
Getting Started: The XOR Problem
x x
1 2
g (x)
1
g (x)
2 > 0 < 0 > 0 < 0
ω ω1
2
ω2 A: (0,0) D: (1,1) B: (0,1) C: (1,0)
- Can’t represent with a single linear separator,
but can with intersection of two: g1(x) = 1 · x1 + 1 · x2 − 1/2 g2(x) = 1 · x1 + 1 · x2 − 3/2
- ω1 =
- x ∈ ℜℓ : g1(x) > 0 AND g2(x) < 0
- ω2 =
- x ∈ ℜℓ : g1(x), g2(x) < 0 OR g1(x), g2(x) > 0
- 3
Getting Started: The XOR Problem (cont’d)
- Let yi =
if gi(x) < 0 1
- therwise
Class (x1, x2) g1(x) y1 g2(x) y2 ω1 B: (0, 1) 1/2 1 −1/2 ω1 C: (1, 0) 1/2 1 −1/2 ω2 A: (0, 0) −1/2 −3/2 ω2 D: (1, 1) 3/2 1 1/2 1
- Now feed y1, y2 into: