
SLIDE 1
Summary: Wavelet Scattering Net
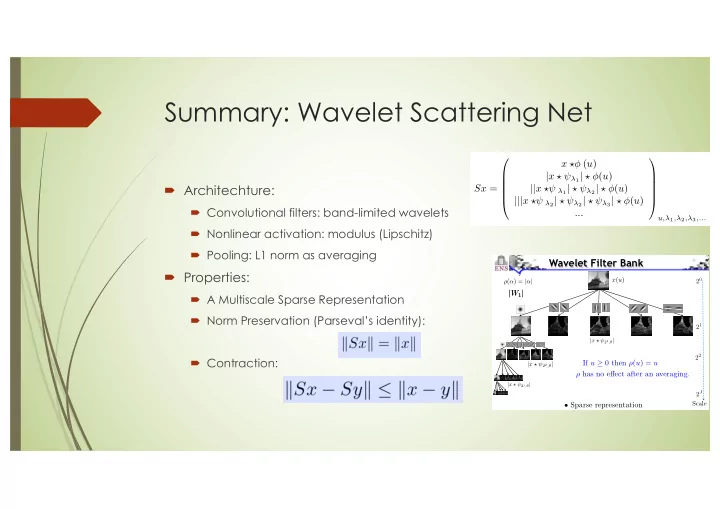
´ Architechture:
´ Convolutional filters: band-limited wavelets ´ Nonlinear activation: modulus (Lipschitz) ´ Pooling: L1 norm as averaging
´ Properties:
´ A Multiscale Sparse Representation ´ Norm Preservation (Parseval’s identity): ´ Contraction:
Sx = x ⇤ (u) |x ⇤ ⇥λ1| ⇤ (u) ||x ⇤⇥ λ1| ⇤ ⇥λ2| ⇤ (u) |||x ⇤⇥ λ2| ⇤ ⇥λ2| ⇤ ⇥λ3| ⇤ (u) ...
u,λ1,λ2,λ3,...
k k )) k Sx
is
20 22 2J |x ? 22,θ|
|W1|
Scale 21
|x ? 21,θ|
|W1|
Wavelet Filter Bank
x(u) ρ(α) = |α|
- Sparse representation
|x ? 2j,θ|
If u ≥ 0 then ρ(u) = u ρ has no effect after an averaging.