
SLIDE 1
U 5: I L 2: C- S 101
Nicole Dalzell June 9, 2015
HT for comparing proportions: p1 = p2
Reporting bullying
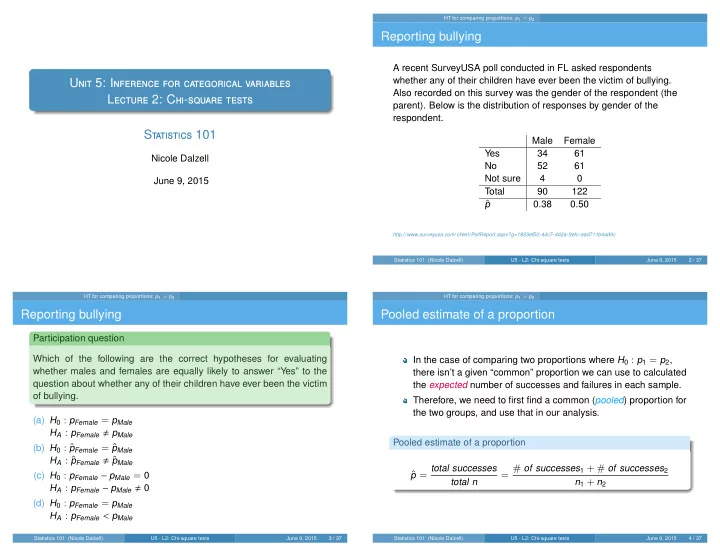
A recent SurveyUSA poll conducted in FL asked respondents whether any of their children have ever been the victim of bullying. Also recorded on this survey was the gender of the respondent (the parent). Below is the distribution of responses by gender of the respondent. Male Female Yes 34 61 No 52 61 Not sure 4 Total 90 122
ˆ
p 0.38 0.50
http://www.surveyusa.com/client/PollReport.aspx?g=1823ef50-44c7-4d2a-9efc-ead711b4ad9c Statistics 101 (Nicole Dalzell) U5 - L2: Chi-square tests June 9, 2015 2 / 37 HT for comparing proportions: p1 = p2
Reporting bullying
Participation question Which of the following are the correct hypotheses for evaluating whether males and females are equally likely to answer “Yes” to the question about whether any of their children have ever been the victim
- f bullying.
(a) H0 : pFemale = pMale HA : pFemale pMale (b) H0 : ˆ pFemale = ˆ pMale HA : ˆ pFemale ˆ pMale (c) H0 : pFemale − pMale = 0 HA : pFemale − pMale 0 (d) H0 : pFemale = pMale HA : pFemale < pMale
Statistics 101 (Nicole Dalzell) U5 - L2: Chi-square tests June 9, 2015 3 / 37 HT for comparing proportions: p1 = p2
Pooled estimate of a proportion
In the case of comparing two proportions where H0 : p1 = p2, there isn’t a given “common” proportion we can use to calculated the expected number of successes and failures in each sample. Therefore, we need to first find a common (pooled) proportion for the two groups, and use that in our analysis. Pooled estimate of a proportion
ˆ
p = total successes total n
= # of successes1 + # of successes2
n1 + n2
Statistics 101 (Nicole Dalzell) U5 - L2: Chi-square tests June 9, 2015 4 / 37