
SLIDE 1
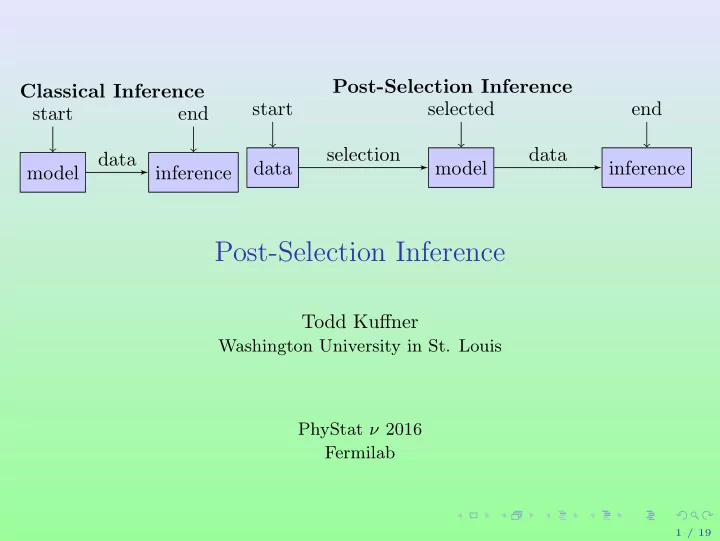
Classical Inference model start inference end data Post-Selection Inference data start model selected inference end selection data
Post-Selection Inference
Todd Kuffner
Washington University in St. Louis PhyStat ν 2016 Fermilab
1 / 19