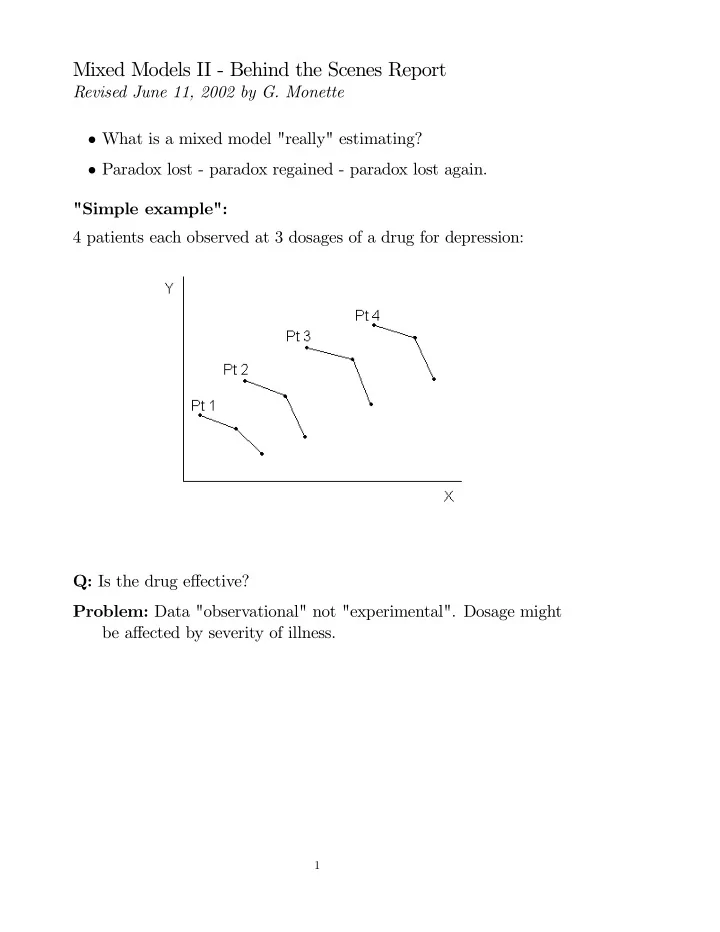

SLIDE 1
Mixed Models II - Behind the Scenes Report
Revised June 11, 2002 by G. Monette
- What is a mixed model "really" estimating?
- Paradox lost - paradox regained - paradox lost again.