
SLIDE 1
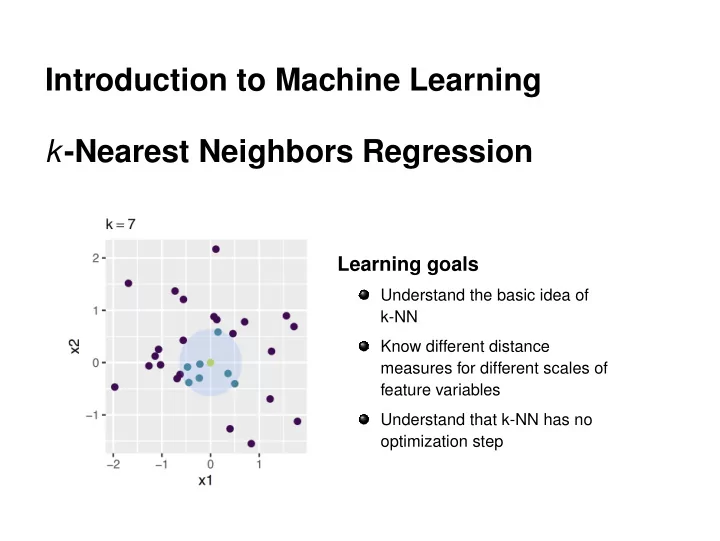
Introduction to Machine Learning k-Nearest Neighbors Regression
Learning goals
Understand the basic idea of k-NN Know different distance measures for different scales of feature variables Understand that k-NN has no
- ptimization step