
SLIDE 1
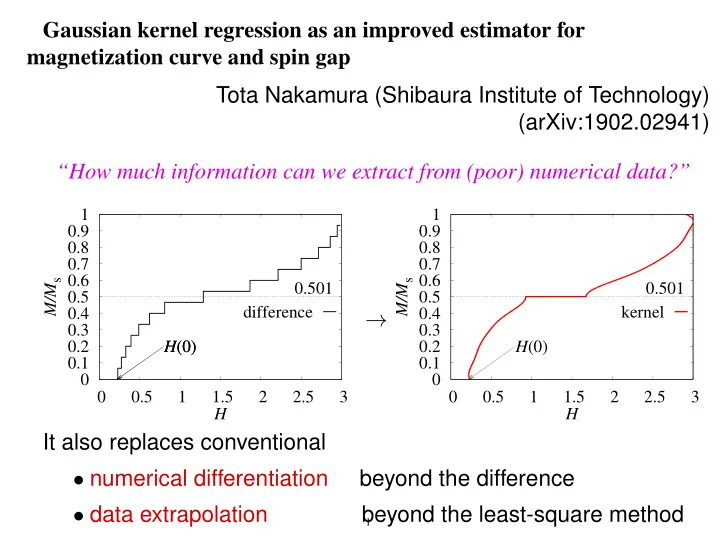
Gaussian kernel regression as an improved estimator for magnetization curve and spin gap Tota Nakamura (Shibaura Institute of Technology) (arXiv:1902.02941) “How much information can we extract from (poor) numerical data?”
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.5 1 1.5 2 2.5 3 H(0) H(0) 0.501 M/Ms H difference 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.5 1 1.5 2 2.5 3 H(0) 0.501 M/Ms H kernel
It also replaces conventional
- numerical differentiation
beyond the difference
- data extrapolation
beyond the least-square method →
1