
SLIDE 1
6 INTRODUCTION TO MULTIVARIABLE CONTROL [3]
6.1 Transfer functions for MIMO systems [3.2]
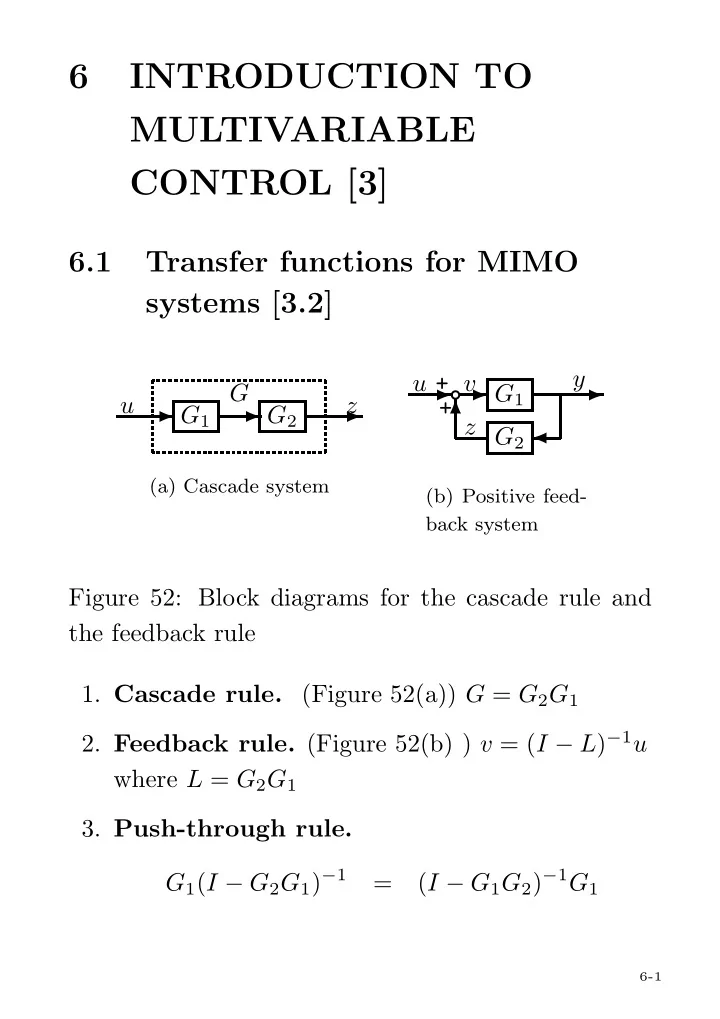
✲ G1 ✲ G2 ✲ G u z
(a) Cascade system
✲❜✲ + + G1 ✲ ♣ ✛ G2 ✻ u y v z
(b) Positive feed- back system
Figure 52: Block diagrams for the cascade rule and the feedback rule
- 1. Cascade rule. (Figure 52(a)) G = G2G1
- 2. Feedback rule. (Figure 52(b) ) v = (I − L)−1u
where L = G2G1
- 3. Push-through rule.
G1(I − G2G1)−1 = (I − G1G2)−1G1
6-1