
SLIDE 1
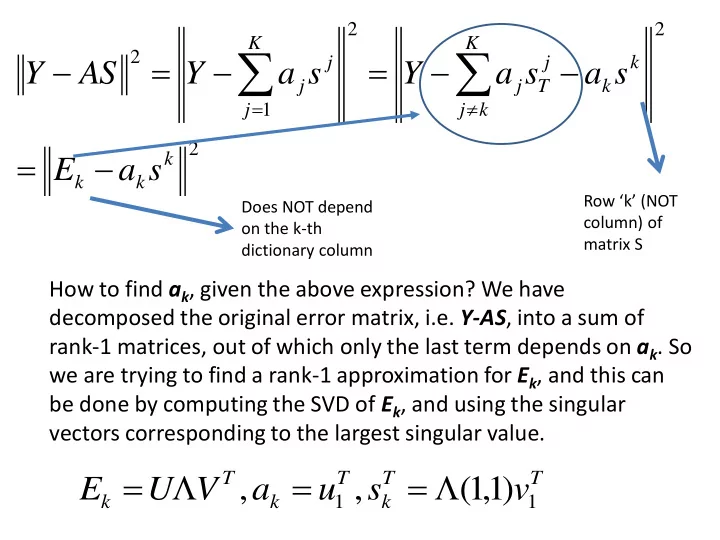
2 2 2 1 2 k k k K k j k k j T j K j j j
s a E s a s a Y s a Y AS Y
Row ‘k’ (NOT column) of matrix S Does NOT depend
- n the k-th
dictionary column
How to find ak, given the above expression? We have decomposed the original error matrix, i.e. Y-AS, into a sum of rank-1 matrices, out of which only the last term depends on ak. So we are trying to find a rank-1 approximation for Ek, and this can be done by computing the SVD of Ek, and using the singular vectors corresponding to the largest singular value.
T T k T k T k
v s u a V U E
1 1