SLIDE 1
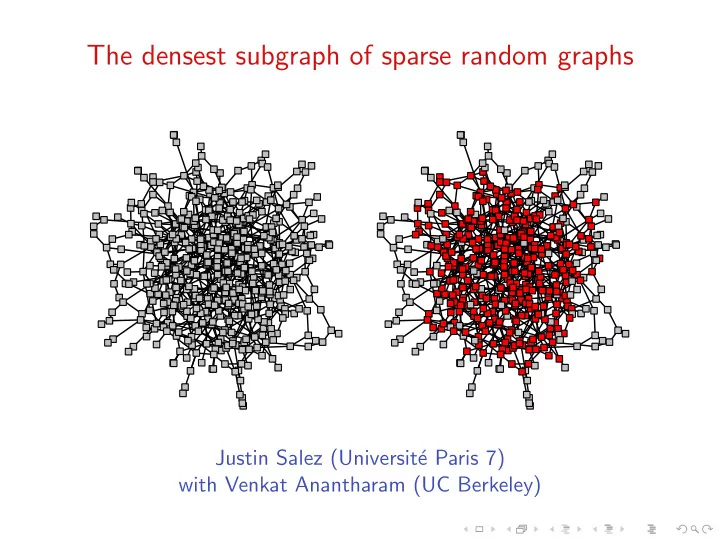
The densest subgraph of sparse random graphs
Justin Salez (Universit´ e Paris 7) with Venkat Anantharam (UC Berkeley)
SLIDE 2
The objective method (Aldous-Steele, 2004)
SLIDE 3
The objective method (Aldous-Steele, 2004)
◮ Context: given a large interacting system (graph), one is
interested in a macroscopic quantity which depends on the microscopic contribution of each particle (vertices).
SLIDE 4
The objective method (Aldous-Steele, 2004)
◮ Context: given a large interacting system (graph), one is
interested in a macroscopic quantity which depends on the microscopic contribution of each particle (vertices).
◮ Key assumption: no long-range interactions, i.e. the
microscopic contribution of each particle is essentially insensitive to remote perturbations of the system.
SLIDE 5
The objective method (Aldous-Steele, 2004)
◮ Context: given a large interacting system (graph), one is
interested in a macroscopic quantity which depends on the microscopic contribution of each particle (vertices).
◮ Key assumption: no long-range interactions, i.e. the
microscopic contribution of each particle is essentially insensitive to remote perturbations of the system.
◮ Expected consequences:
SLIDE 6 The objective method (Aldous-Steele, 2004)
◮ Context: given a large interacting system (graph), one is
interested in a macroscopic quantity which depends on the microscopic contribution of each particle (vertices).
◮ Key assumption: no long-range interactions, i.e. the
microscopic contribution of each particle is essentially insensitive to remote perturbations of the system.
◮ Expected consequences:
- 1. efficient approximability by local distributed algorithms;
SLIDE 7 The objective method (Aldous-Steele, 2004)
◮ Context: given a large interacting system (graph), one is
interested in a macroscopic quantity which depends on the microscopic contribution of each particle (vertices).
◮ Key assumption: no long-range interactions, i.e. the
microscopic contribution of each particle is essentially insensitive to remote perturbations of the system.
◮ Expected consequences:
- 1. efficient approximability by local distributed algorithms;
- 2. existence of an infinite-volume limit.
SLIDE 8 The objective method (Aldous-Steele, 2004)
◮ Context: given a large interacting system (graph), one is
interested in a macroscopic quantity which depends on the microscopic contribution of each particle (vertices).
◮ Key assumption: no long-range interactions, i.e. the
microscopic contribution of each particle is essentially insensitive to remote perturbations of the system.
◮ Expected consequences:
- 1. efficient approximability by local distributed algorithms;
- 2. existence of an infinite-volume limit.
◮ Idea: formalize that via local weak convergence, and use this
framework to replace the asymptotic study of large graphs by the direct analysis of their infinite-volume limits.
SLIDE 9
Local convergence around a fixed root
SLIDE 10
Local convergence around a fixed root
(G, o) : countable, locally finite, connected rooted graph
SLIDE 11
Local convergence around a fixed root
(G, o) : countable, locally finite, connected rooted graph [G, o]R : ball of radius R around o in G
SLIDE 12
Local convergence around a fixed root
(G, o) : countable, locally finite, connected rooted graph [G, o]R : ball of radius R around o in G
R
SLIDE 13
Local convergence around a fixed root
(G, o) : countable, locally finite, connected rooted graph [G, o]R : ball of radius R around o in G
R
(Gn, on) − − − →
n→∞ (G, o)
SLIDE 14
Local convergence around a fixed root
(G, o) : countable, locally finite, connected rooted graph [G, o]R : ball of radius R around o in G
R
(Gn, on) − − − →
n→∞ (G, o) if for each fixed R, there is nR ∈ N such that
n ≥ nR = ⇒ [Gn, on]R ≡ [G, o]R
SLIDE 15
Local weak convergence (Benjamini-Schramm, 2001)
G⋆ = {locally finite connected rooted graphs}.
SLIDE 16
Local weak convergence (Benjamini-Schramm, 2001)
G⋆ = {locally finite connected rooted graphs}. G = (V , E) : finite unrooted, possibly disconnected graph.
SLIDE 17
Local weak convergence (Benjamini-Schramm, 2001)
G⋆ = {locally finite connected rooted graphs}. G = (V , E) : finite unrooted, possibly disconnected graph. Consider the law on G⋆ obtained by choosing a root o ∈ V uniformly at random, and restricting to its connected component:
SLIDE 18 Local weak convergence (Benjamini-Schramm, 2001)
G⋆ = {locally finite connected rooted graphs}. G = (V , E) : finite unrooted, possibly disconnected graph. Consider the law on G⋆ obtained by choosing a root o ∈ V uniformly at random, and restricting to its connected component: LG := 1 |V |
δ[G,o].
SLIDE 19 Local weak convergence (Benjamini-Schramm, 2001)
G⋆ = {locally finite connected rooted graphs}. G = (V , E) : finite unrooted, possibly disconnected graph. Consider the law on G⋆ obtained by choosing a root o ∈ V uniformly at random, and restricting to its connected component: LG := 1 |V |
δ[G,o]. LG is an element of P(G⋆) := {probability measures on G⋆}.
SLIDE 20 Local weak convergence (Benjamini-Schramm, 2001)
G⋆ = {locally finite connected rooted graphs}. G = (V , E) : finite unrooted, possibly disconnected graph. Consider the law on G⋆ obtained by choosing a root o ∈ V uniformly at random, and restricting to its connected component: LG := 1 |V |
δ[G,o]. LG is an element of P(G⋆) := {probability measures on G⋆}. {Gn}n≥1 : sequence of finite graphs.
SLIDE 21 Local weak convergence (Benjamini-Schramm, 2001)
G⋆ = {locally finite connected rooted graphs}. G = (V , E) : finite unrooted, possibly disconnected graph. Consider the law on G⋆ obtained by choosing a root o ∈ V uniformly at random, and restricting to its connected component: LG := 1 |V |
δ[G,o]. LG is an element of P(G⋆) := {probability measures on G⋆}. {Gn}n≥1 : sequence of finite graphs. If {LGn}n≥1 admits a weak limit L ∈ P(G⋆), then call L the local weak limit of {Gn}n≥1.
SLIDE 22 Local weak convergence (Benjamini-Schramm, 2001)
G⋆ = {locally finite connected rooted graphs}. G = (V , E) : finite unrooted, possibly disconnected graph. Consider the law on G⋆ obtained by choosing a root o ∈ V uniformly at random, and restricting to its connected component: LG := 1 |V |
δ[G,o]. LG is an element of P(G⋆) := {probability measures on G⋆}. {Gn}n≥1 : sequence of finite graphs. If {LGn}n≥1 admits a weak limit L ∈ P(G⋆), then call L the local weak limit of {Gn}n≥1. ◮ L describes the local geometry of Gn around a random node
SLIDE 23
Examples of local weak limits
SLIDE 24
Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
SLIDE 25
Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
SLIDE 26
Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
SLIDE 27
Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
SLIDE 28
Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
SLIDE 29 Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
◮ Gn = Erd˝
enyi graph with pn = c
n on n nodes
SLIDE 30 Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
◮ Gn = Erd˝
enyi graph with pn = c
n on n nodes
L = law of a Galton-Watson tree with degree Poisson(c)
SLIDE 31 Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
◮ Gn = Erd˝
enyi graph with pn = c
n on n nodes
L = law of a Galton-Watson tree with degree Poisson(c)
◮ Gn = random graph with degree distribution π on n nodes
SLIDE 32 Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
◮ Gn = Erd˝
enyi graph with pn = c
n on n nodes
L = law of a Galton-Watson tree with degree Poisson(c)
◮ Gn = random graph with degree distribution π on n nodes
L = law of a Galton-Watson tree with degree distribution π
SLIDE 33 Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
◮ Gn = Erd˝
enyi graph with pn = c
n on n nodes
L = law of a Galton-Watson tree with degree Poisson(c)
◮ Gn = random graph with degree distribution π on n nodes
L = law of a Galton-Watson tree with degree distribution π
◮ Gn = uniform random tree on n nodes
SLIDE 34 Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
◮ Gn = Erd˝
enyi graph with pn = c
n on n nodes
L = law of a Galton-Watson tree with degree Poisson(c)
◮ Gn = random graph with degree distribution π on n nodes
L = law of a Galton-Watson tree with degree distribution π
◮ Gn = uniform random tree on n nodes
L = Infinite Skeleton Tree (Grimmett, 1980)
SLIDE 35 Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
◮ Gn = Erd˝
enyi graph with pn = c
n on n nodes
L = law of a Galton-Watson tree with degree Poisson(c)
◮ Gn = random graph with degree distribution π on n nodes
L = law of a Galton-Watson tree with degree distribution π
◮ Gn = uniform random tree on n nodes
L = Infinite Skeleton Tree (Grimmett, 1980)
◮ Gn = preferential attachment graph on n nodes
SLIDE 36 Examples of local weak limits
Note: graphs must be sparse, i.e. |E| ≍ |V |
◮ Gn = box of size n × . . . × n in Zd
L = dirac at (Zd, 0)
◮ Gn = random d−regular graph on n nodes
L = dirac at the d−regular infinite rooted tree
◮ Gn = Erd˝
enyi graph with pn = c
n on n nodes
L = law of a Galton-Watson tree with degree Poisson(c)
◮ Gn = random graph with degree distribution π on n nodes
L = law of a Galton-Watson tree with degree distribution π
◮ Gn = uniform random tree on n nodes
L = Infinite Skeleton Tree (Grimmett, 1980)
◮ Gn = preferential attachment graph on n nodes
L = Polya-point graph (Berger-Borgs-Chayes-Sabery, 2009)
SLIDE 37
An illustration: the nullity of large graphs
SLIDE 38
An illustration: the nullity of large graphs
µG({0}) = dim ker(AG)
|V |
.
SLIDE 39
An illustration: the nullity of large graphs
µG({0}) = dim ker(AG)
|V |
. Asymptotics when G is large ?
SLIDE 40 An illustration: the nullity of large graphs
µG({0}) = dim ker(AG)
|V |
. Asymptotics when G is large ? Conjecture (Bauer-Golinelli 2001). For Gn : Erd˝
enyi
n
µGn({0}) − − − →
n→∞
λ∗ + e−cλ∗ + cλ∗e−cλ∗ − 1, where λ∗ ∈ [0, 1] is the smallest root of λ = e−ce−cλ.
SLIDE 41 An illustration: the nullity of large graphs
µG({0}) = dim ker(AG)
|V |
. Asymptotics when G is large ? Conjecture (Bauer-Golinelli 2001). For Gn : Erd˝
enyi
n
µGn({0}) − − − →
n→∞
λ∗ + e−cλ∗ + cλ∗e−cλ∗ − 1, where λ∗ ∈ [0, 1] is the smallest root of λ = e−ce−cλ. Theorem (Bordenave-Lelarge-S., 2011)
SLIDE 42 An illustration: the nullity of large graphs
µG({0}) = dim ker(AG)
|V |
. Asymptotics when G is large ? Conjecture (Bauer-Golinelli 2001). For Gn : Erd˝
enyi
n
µGn({0}) − − − →
n→∞
λ∗ + e−cλ∗ + cλ∗e−cλ∗ − 1, where λ∗ ∈ [0, 1] is the smallest root of λ = e−ce−cλ. Theorem (Bordenave-Lelarge-S., 2011)
⇒ µGn({0}) → µL({0}).
SLIDE 43 An illustration: the nullity of large graphs
µG({0}) = dim ker(AG)
|V |
. Asymptotics when G is large ? Conjecture (Bauer-Golinelli 2001). For Gn : Erd˝
enyi
n
µGn({0}) − − − →
n→∞
λ∗ + e−cλ∗ + cλ∗e−cλ∗ − 1, where λ∗ ∈ [0, 1] is the smallest root of λ = e−ce−cλ. Theorem (Bordenave-Lelarge-S., 2011)
⇒ µGn({0}) → µL({0}).
- 2. When L = Galton-Watson(π),
µL({0}) = min
λ=λ∗∗
- f ′(1)λλ∗ + f (1 − λ) + f (1 − λ∗) − 1
- ,
where f (z) =
n πnzn and λ∗ = f ′(1 − λ)/f ′(1).
SLIDE 44
Continuity with respect to local weak convergence
SLIDE 45
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
SLIDE 46
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L)
SLIDE 47
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
SLIDE 48
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
◮ Analytic implication: Φ admits a limit along most sparse
graph sequences. The distributional self-similarity of L may even allow for an explicit determination of Φ(L).
SLIDE 49
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
◮ Analytic implication: Φ admits a limit along most sparse
graph sequences. The distributional self-similarity of L may even allow for an explicit determination of Φ(L).
◮ Examples:
SLIDE 50
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
◮ Analytic implication: Φ admits a limit along most sparse
graph sequences. The distributional self-similarity of L may even allow for an explicit determination of Φ(L).
◮ Examples: number of spanning trees (Lyons, 2005),
SLIDE 51
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
◮ Analytic implication: Φ admits a limit along most sparse
graph sequences. The distributional self-similarity of L may even allow for an explicit determination of Φ(L).
◮ Examples: number of spanning trees (Lyons, 2005), spectrum
and rank (Bordenave-Lelarge-S, 2011),
SLIDE 52
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
◮ Analytic implication: Φ admits a limit along most sparse
graph sequences. The distributional self-similarity of L may even allow for an explicit determination of Φ(L).
◮ Examples: number of spanning trees (Lyons, 2005), spectrum
and rank (Bordenave-Lelarge-S, 2011), matching polynomial (idem, 2013),
SLIDE 53
Continuity with respect to local weak convergence
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry only.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
◮ Analytic implication: Φ admits a limit along most sparse
graph sequences. The distributional self-similarity of L may even allow for an explicit determination of Φ(L).
◮ Examples: number of spanning trees (Lyons, 2005), spectrum
and rank (Bordenave-Lelarge-S, 2011), matching polynomial (idem, 2013), Ising models (Dembo-Montanari-Sun, 2013)...
SLIDE 54
The densest subgraph problem
SLIDE 55
The densest subgraph problem
Fix a finite graph G = (V , E)
SLIDE 56 The densest subgraph problem
Fix a finite graph G = (V , E) Densest subgraph : H⋆ = argmax
|H| : H ⊆ V
SLIDE 57 The densest subgraph problem
Fix a finite graph G = (V , E) Densest subgraph : H⋆ = argmax
|H| : H ⊆ V
- Maximum subgraph density : ̺⋆ = max
- |E(H)|
|H| : H ⊆ V
SLIDE 58 The densest subgraph problem
Fix a finite graph G = (V , E) Densest subgraph : H⋆ = argmax
|H| : H ⊆ V
- Maximum subgraph density : ̺⋆ = max
- |E(H)|
|H| : H ⊆ V
10
SLIDE 59
The densest subgraph problem on large sparse graphs
SLIDE 60
The densest subgraph problem on large sparse graphs
SLIDE 61
The densest subgraph problem on large sparse graphs
SLIDE 62
Load balancing
SLIDE 63
Load balancing
An allocation on G is a function θ: E → [0, 1] satisfying θ(i, j) + θ(j, i) = 1
SLIDE 64 Load balancing
An allocation on G is a function θ: E → [0, 1] satisfying θ(i, j) + θ(j, i) = 1 The induced load at i ∈ V is ∂θ(i) =
θ(j, i)
SLIDE 65 Load balancing
An allocation on G is a function θ: E → [0, 1] satisfying θ(i, j) + θ(j, i) = 1 The induced load at i ∈ V is ∂θ(i) =
θ(j, i) The allocation is balanced if for each (i, j) ∈ E ∂θ(i) < ∂θ(j) = ⇒ θ(i, j) = 0
SLIDE 66
From local to global optimality
SLIDE 67 From local to global optimality
- Claim. For an allocation θ, the following are equivalent:
SLIDE 68 From local to global optimality
- Claim. For an allocation θ, the following are equivalent:
- 1. θ is balanced
SLIDE 69 From local to global optimality
- Claim. For an allocation θ, the following are equivalent:
- 1. θ is balanced
- 2. θ minimizes
i (∂θ(i))2.
SLIDE 70 From local to global optimality
- Claim. For an allocation θ, the following are equivalent:
- 1. θ is balanced
- 2. θ minimizes
i (∂θ(i))2.
i f (∂θ(i)) for any convex function f : R → R.
SLIDE 71 From local to global optimality
- Claim. For an allocation θ, the following are equivalent:
- 1. θ is balanced
- 2. θ minimizes
i (∂θ(i))2.
i f (∂θ(i)) for any convex function f : R → R.
Corollary 1. Balanced allocations always exist.
SLIDE 72 From local to global optimality
- Claim. For an allocation θ, the following are equivalent:
- 1. θ is balanced
- 2. θ minimizes
i (∂θ(i))2.
i f (∂θ(i)) for any convex function f : R → R.
Corollary 1. Balanced allocations always exist. Corollary 2. They all induce the same loads ∂θ: V → [0, ∞).
SLIDE 73 From local to global optimality
- Claim. For an allocation θ, the following are equivalent:
- 1. θ is balanced
- 2. θ minimizes
i (∂θ(i))2.
i f (∂θ(i)) for any convex function f : R → R.
Corollary 1. Balanced allocations always exist. Corollary 2. They all induce the same loads ∂θ: V → [0, ∞). Corollary 3. Balanced loads solve the densest subgraph problem:
SLIDE 74 From local to global optimality
- Claim. For an allocation θ, the following are equivalent:
- 1. θ is balanced
- 2. θ minimizes
i (∂θ(i))2.
i f (∂θ(i)) for any convex function f : R → R.
Corollary 1. Balanced allocations always exist. Corollary 2. They all induce the same loads ∂θ: V → [0, ∞). Corollary 3. Balanced loads solve the densest subgraph problem: max
i∈V ∂θ(i) = ̺⋆
and argmax
i∈V
∂θ(i) = H⋆
SLIDE 75
Example
SLIDE 76 Example
3 7 2 2 3 4 8 8 6 7 5 5 5 5 5 5 8 2 8 7 3 2 2 8 5 5 9 3 4 7 6 7 3 1 10 10 10 10 10 10 10 10 10 10 5 5 5 5 8 9 10 10 10 5 5 5 5 10 5 5 5 5 10 8 2 2 9 1 5 5 1 10
SLIDE 77 Example
1.5 1.5 1.5 1.5 1.5 1.5 1.5 1.5 1 1 1 1 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.6 1.6 1.6 1.6 1.6 1.5 1.5
SLIDE 78 Example
1.5 1.5 1.5 1.5 1.5 1.5 1.5 1.5 1 1 1 1 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.6 1.6 1.6 1.6 1.6 1.5 1.5
SLIDE 79
How do those ‘densities” look on a large sparse graph ?
SLIDE 80
How do those ‘densities” look on a large sparse graph ?
SLIDE 81
How do those ‘densities” look on a large sparse graph ?
SLIDE 82
Density profile of a random graph with average degree 3
SLIDE 83
Density profile of a random graph with average degree 3
|V | = 100
SLIDE 84
Density profile of a random graph with average degree 3
|V | = 100 |V | = 10000
SLIDE 85
Density profile of a random graph with average degree 4
SLIDE 86
Density profile of a random graph with average degree 4
|V | = 100
SLIDE 87
Density profile of a random graph with average degree 4
|V | = 100 |V | = 10000
SLIDE 88
The conjecture (Hajek, 1990)
SLIDE 89
The conjecture (Hajek, 1990)
∂Θ(G, o) : load induced at o by any balanced allocation on G.
SLIDE 90 The conjecture (Hajek, 1990)
∂Θ(G, o) : load induced at o by any balanced allocation on G. Define the density profile of G = (V , E) as ΛG = 1 |V |
δ∂Θ(G,o) ∈ P(R).
SLIDE 91 The conjecture (Hajek, 1990)
∂Θ(G, o) : load induced at o by any balanced allocation on G. Define the density profile of G = (V , E) as ΛG = 1 |V |
δ∂Θ(G,o) ∈ P(R). Conjecture: Gn Erd˝
enyi
n
SLIDE 92 The conjecture (Hajek, 1990)
∂Θ(G, o) : load induced at o by any balanced allocation on G. Define the density profile of G = (V , E) as ΛG = 1 |V |
δ∂Θ(G,o) ∈ P(R). Conjecture: Gn Erd˝
enyi
n
- ; c fixed, n → ∞
- 1. ΛGn concentrates around a deterministic Λ ∈ P(R)
SLIDE 93 The conjecture (Hajek, 1990)
∂Θ(G, o) : load induced at o by any balanced allocation on G. Define the density profile of G = (V , E) as ΛG = 1 |V |
δ∂Θ(G,o) ∈ P(R). Conjecture: Gn Erd˝
enyi
n
- ; c fixed, n → ∞
- 1. ΛGn concentrates around a deterministic Λ ∈ P(R)
- 2. ̺⋆(Gn)
P
− − − →
n→∞ sup{t ∈ R: Λ(t, +∞) > 0}
SLIDE 94
Result 1 : the density profile of sparse graphs
SLIDE 95 Result 1 : the density profile of sparse graphs
- Theorem. Assume that L [deg(G, o)] < ∞.
SLIDE 96 Result 1 : the density profile of sparse graphs
- Theorem. Assume that L [deg(G, o)] < ∞. Then,
Gn
loc.
− − − →
n→∞ L
= ⇒ ΛGn
P(R)
− − − →
n→∞ ΛL
SLIDE 97 Result 1 : the density profile of sparse graphs
- Theorem. Assume that L [deg(G, o)] < ∞. Then,
Gn
loc.
− − − →
n→∞ L
= ⇒ ΛGn
P(R)
− − − →
n→∞ ΛL
where ΛL is the solution to a certain optimization problem on L.
SLIDE 98 Result 1 : the density profile of sparse graphs
- Theorem. Assume that L [deg(G, o)] < ∞. Then,
Gn
loc.
− − − →
n→∞ L
= ⇒ ΛGn
P(R)
− − − →
n→∞ ΛL
where ΛL is the solution to a certain optimization problem on L. Specifically, the excess function Φ: t →
SLIDE 99 Result 1 : the density profile of sparse graphs
- Theorem. Assume that L [deg(G, o)] < ∞. Then,
Gn
loc.
− − − →
n→∞ L
= ⇒ ΛGn
P(R)
− − − →
n→∞ ΛL
where ΛL is the solution to a certain optimization problem on L. Specifically, the excess function Φ: t →
Φ(t) = max
f : G⋆→[0,1]
2L
f (G, i) ∧ f (G, o)
SLIDE 100
Result 2 : maximum subgraph density of sparse graphs
SLIDE 101
Result 2 : maximum subgraph density of sparse graphs
Extend the definition of ̺⋆ to local weak limits by ̺⋆(L) := sup ess ΛL = sup{t : Φ(t) > 0}
SLIDE 102
Result 2 : maximum subgraph density of sparse graphs
Extend the definition of ̺⋆ to local weak limits by ̺⋆(L) := sup ess ΛL = sup{t : Φ(t) > 0} In light of previous result, one expects a continuity principle :
SLIDE 103
Result 2 : maximum subgraph density of sparse graphs
Extend the definition of ̺⋆ to local weak limits by ̺⋆(L) := sup ess ΛL = sup{t : Φ(t) > 0} In light of previous result, one expects a continuity principle : Gn
loc.
− − − →
n→∞ L
= ⇒ ̺⋆(Gn) − − − →
n→∞ ̺⋆(L)
SLIDE 104
Result 2 : maximum subgraph density of sparse graphs
Extend the definition of ̺⋆ to local weak limits by ̺⋆(L) := sup ess ΛL = sup{t : Φ(t) > 0} In light of previous result, one expects a continuity principle : Gn
loc.
− − − →
n→∞ L
= ⇒ ̺⋆(Gn) − − − →
n→∞ ̺⋆(L)
Counter-example:
SLIDE 105
Result 2 : maximum subgraph density of sparse graphs
Extend the definition of ̺⋆ to local weak limits by ̺⋆(L) := sup ess ΛL = sup{t : Φ(t) > 0} In light of previous result, one expects a continuity principle : Gn
loc.
− − − →
n→∞ L
= ⇒ ̺⋆(Gn) − − − →
n→∞ ̺⋆(L)
Counter-example: adding a large but fixed clique to Gn will arbitrarily boost ̺⋆(Gn) without affecting convergence Gn → L.
SLIDE 106 Result 2 : maximum subgraph density of sparse graphs
Extend the definition of ̺⋆ to local weak limits by ̺⋆(L) := sup ess ΛL = sup{t : Φ(t) > 0} In light of previous result, one expects a continuity principle : Gn
loc.
− − − →
n→∞ L
= ⇒ ̺⋆(Gn) − − − →
n→∞ ̺⋆(L)
Counter-example: adding a large but fixed clique to Gn will arbitrarily boost ̺⋆(Gn) without affecting convergence Gn → L.
- Theorem. Gn uniform with degree distribution {πk}k∈N.
SLIDE 107 Result 2 : maximum subgraph density of sparse graphs
Extend the definition of ̺⋆ to local weak limits by ̺⋆(L) := sup ess ΛL = sup{t : Φ(t) > 0} In light of previous result, one expects a continuity principle : Gn
loc.
− − − →
n→∞ L
= ⇒ ̺⋆(Gn) − − − →
n→∞ ̺⋆(L)
Counter-example: adding a large but fixed clique to Gn will arbitrarily boost ̺⋆(Gn) without affecting convergence Gn → L.
- Theorem. Gn uniform with degree distribution {πk}k∈N.
Assume degrees have light tail, i.e. lim sup
k→∞
π1/k
k
< 1.
SLIDE 108 Result 2 : maximum subgraph density of sparse graphs
Extend the definition of ̺⋆ to local weak limits by ̺⋆(L) := sup ess ΛL = sup{t : Φ(t) > 0} In light of previous result, one expects a continuity principle : Gn
loc.
− − − →
n→∞ L
= ⇒ ̺⋆(Gn) − − − →
n→∞ ̺⋆(L)
Counter-example: adding a large but fixed clique to Gn will arbitrarily boost ̺⋆(Gn) without affecting convergence Gn → L.
- Theorem. Gn uniform with degree distribution {πk}k∈N.
Assume degrees have light tail, i.e. lim sup
k→∞
π1/k
k
< 1. Then, ̺⋆(Gn) − − − →
n→∞ ̺⋆(L), where L = Galton-Watson(π).
SLIDE 109
Result 3 : the case of Galton-Watson trees
SLIDE 110 Result 3 : the case of Galton-Watson trees
- Theorem. In the case where L = Galton-Watson(π),
Φ(t) = max
Q∈P([0,1])
E[D] 2 P (ξ1 + ξ2 > 1) − tP (ξ1 + · · · + ξD > t)
SLIDE 111 Result 3 : the case of Galton-Watson trees
- Theorem. In the case where L = Galton-Watson(π),
Φ(t) = max
Q∈P([0,1])
E[D] 2 P (ξ1 + ξ2 > 1) − tP (ξ1 + · · · + ξD > t)
- where D ∼ π and {ξk}k≥1 are iid with law Q, independent of D.
SLIDE 112 Result 3 : the case of Galton-Watson trees
- Theorem. In the case where L = Galton-Watson(π),
Φ(t) = max
Q∈P([0,1])
E[D] 2 P (ξ1 + ξ2 > 1) − tP (ξ1 + · · · + ξD > t)
- where D ∼ π and {ξk}k≥1 are iid with law Q, independent of D.
The maximum is over all choices of Q ∈ P([0, 1]) such that
SLIDE 113 Result 3 : the case of Galton-Watson trees
- Theorem. In the case where L = Galton-Watson(π),
Φ(t) = max
Q∈P([0,1])
E[D] 2 P (ξ1 + ξ2 > 1) − tP (ξ1 + · · · + ξD > t)
- where D ∼ π and {ξk}k≥1 are iid with law Q, independent of D.
The maximum is over all choices of Q ∈ P([0, 1]) such that ξ d = [1 − t + ξ1 + · · · + ξD]1
SLIDE 114 Result 3 : the case of Galton-Watson trees
- Theorem. In the case where L = Galton-Watson(π),
Φ(t) = max
Q∈P([0,1])
E[D] 2 P (ξ1 + ξ2 > 1) − tP (ξ1 + · · · + ξD > t)
- where D ∼ π and {ξk}k≥1 are iid with law Q, independent of D.
The maximum is over all choices of Q ∈ P([0, 1]) such that ξ d = [1 − t + ξ1 + · · · + ξD]1 where [•]1
0 denotes projection onto [0, 1] : [x]1 0 =
if x < 0 x if x ∈ [0, 1] 1 if x > 1
SLIDE 115 Result 3 : the case of Galton-Watson trees
- Theorem. In the case where L = Galton-Watson(π),
Φ(t) = max
Q∈P([0,1])
E[D] 2 P (ξ1 + ξ2 > 1) − tP (ξ1 + · · · + ξD > t)
- where D ∼ π and {ξk}k≥1 are iid with law Q, independent of D.
The maximum is over all choices of Q ∈ P([0, 1]) such that ξ d = [1 − t + ξ1 + · · · + ξD]1 where [•]1
0 denotes projection onto [0, 1] : [x]1 0 =
if x < 0 x if x ∈ [0, 1] 1 if x > 1 Distributional fixed-point equation : can be solved numerically.
SLIDE 116
An explicit formula
SLIDE 117 An explicit formula
Gn : Erd˝
enyi
n
SLIDE 118 An explicit formula
Gn : Erd˝
enyi
n
SLIDE 119 An explicit formula
Gn : Erd˝
enyi
n
Question: does Gn contain a k−dense subgraph?
SLIDE 120 An explicit formula
Gn : Erd˝
enyi
n
Question: does Gn contain a k−dense subgraph? Define fk(x) = ex −
k!
SLIDE 121 An explicit formula
Gn : Erd˝
enyi
n
Question: does Gn contain a k−dense subgraph? Define fk(x) = ex −
k!
xex fk−1(x), where x unique solution to xfk−1(x) fk(x)
= 2k.
SLIDE 122 An explicit formula
Gn : Erd˝
enyi
n
Question: does Gn contain a k−dense subgraph? Define fk(x) = ex −
k!
xex fk−1(x), where x unique solution to xfk−1(x) fk(x)
= 2k.
- Theorem. With probability tending to one as n → ∞,
SLIDE 123 An explicit formula
Gn : Erd˝
enyi
n
Question: does Gn contain a k−dense subgraph? Define fk(x) = ex −
k!
xex fk−1(x), where x unique solution to xfk−1(x) fk(x)
= 2k.
- Theorem. With probability tending to one as n → ∞,
◮ If c < c∗ then Gn does not contain a k−dense subgraph
SLIDE 124 An explicit formula
Gn : Erd˝
enyi
n
Question: does Gn contain a k−dense subgraph? Define fk(x) = ex −
k!
xex fk−1(x), where x unique solution to xfk−1(x) fk(x)
= 2k.
- Theorem. With probability tending to one as n → ∞,
◮ If c < c∗ then Gn does not contain a k−dense subgraph ◮ If c > c∗ then Gn contains a k−dense subgraph
SLIDE 125 An explicit formula
Gn : Erd˝
enyi
n
Question: does Gn contain a k−dense subgraph? Define fk(x) = ex −
k!
xex fk−1(x), where x unique solution to xfk−1(x) fk(x)
= 2k.
- Theorem. With probability tending to one as n → ∞,
◮ If c < c∗ then Gn does not contain a k−dense subgraph ◮ If c > c∗ then Gn contains a k−dense subgraph
k 2 3 4 5 6 7 8 9 10 c∗ 3.59 5.76 7.84 9.90 11.93 13.95 15.97 17.98 19.98
SLIDE 126
A few words on the proof
SLIDE 127
A few words on the proof
Microscopic contribution:
SLIDE 128
A few words on the proof
Microscopic contribution: ∂Θ(G, o)
SLIDE 129
A few words on the proof
Microscopic contribution: ∂Θ(G, o) Hope: ∂Θ(G, o) is insensitive to what lies far away from o:
SLIDE 130 A few words on the proof
Microscopic contribution: ∂Θ(G, o) Hope: ∂Θ(G, o) is insensitive to what lies far away from o: [G, o]R ≡ [G ′, o′]R = ⇒
- ∂Θ(G, o) − ∂Θ(G ′, o′)
- ≤ f (R),
where f (R) → 0 as R → ∞.
SLIDE 131 A few words on the proof
Microscopic contribution: ∂Θ(G, o) Hope: ∂Θ(G, o) is insensitive to what lies far away from o: [G, o]R ≡ [G ′, o′]R = ⇒
- ∂Θ(G, o) − ∂Θ(G ′, o′)
- ≤ f (R),
where f (R) → 0 as R → ∞. Counter-example: let G be a d−regular graph with girth > R
SLIDE 132 A few words on the proof
Microscopic contribution: ∂Θ(G, o) Hope: ∂Θ(G, o) is insensitive to what lies far away from o: [G, o]R ≡ [G ′, o′]R = ⇒
- ∂Θ(G, o) − ∂Θ(G ′, o′)
- ≤ f (R),
where f (R) → 0 as R → ∞. Counter-example: let G be a d−regular graph with girth > R
2
SLIDE 133 A few words on the proof
Microscopic contribution: ∂Θ(G, o) Hope: ∂Θ(G, o) is insensitive to what lies far away from o: [G, o]R ≡ [G ′, o′]R = ⇒
- ∂Θ(G, o) − ∂Θ(G ′, o′)
- ≤ f (R),
where f (R) → 0 as R → ∞. Counter-example: let G be a d−regular graph with girth > R
2
SLIDE 134 A few words on the proof
Microscopic contribution: ∂Θ(G, o) Hope: ∂Θ(G, o) is insensitive to what lies far away from o: [G, o]R ≡ [G ′, o′]R = ⇒
- ∂Θ(G, o) − ∂Θ(G ′, o′)
- ≤ f (R),
where f (R) → 0 as R → ∞. Counter-example: let G be a d−regular graph with girth > R
2
- [G, o]R is a tree
- ∂Θ ≤ ̺⋆ < 1 on any tree
SLIDE 135 A few words on the proof
Microscopic contribution: ∂Θ(G, o) Hope: ∂Θ(G, o) is insensitive to what lies far away from o: [G, o]R ≡ [G ′, o′]R = ⇒
- ∂Θ(G, o) − ∂Θ(G ′, o′)
- ≤ f (R),
where f (R) → 0 as R → ∞. Counter-example: let G be a d−regular graph with girth > R
2
- [G, o]R is a tree
- ∂Θ ≤ ̺⋆ < 1 on any tree
◮ Balanced loads exhibit long-range dependences !
SLIDE 136
Solution : relaxed load balancing
SLIDE 137
Solution : relaxed load balancing
ε > 0 : perturbative parameter
SLIDE 138 Solution : relaxed load balancing
ε > 0 : perturbative parameter
- Definition. An allocation θ on G = (V , E) is ε−balanced if
θ(i, j) = 1 2 + ∂θ(i) − ∂θ(j) 2ε 1
SLIDE 139 Solution : relaxed load balancing
ε > 0 : perturbative parameter
- Definition. An allocation θ on G = (V , E) is ε−balanced if
θ(i, j) = 1 2 + ∂θ(i) − ∂θ(j) 2ε 1 In particular, ∂θ(i) ≤ ∂θ(j) − ε = ⇒ θ(i, j) = 0.
SLIDE 140 Solution : relaxed load balancing
ε > 0 : perturbative parameter
- Definition. An allocation θ on G = (V , E) is ε−balanced if
θ(i, j) = 1 2 + ∂θ(i) − ∂θ(j) 2ε 1 In particular, ∂θ(i) ≤ ∂θ(j) − ε = ⇒ θ(i, j) = 0. Claim 1. There exists a unique ε−balanced allocation Θε.
SLIDE 141 Solution : relaxed load balancing
ε > 0 : perturbative parameter
- Definition. An allocation θ on G = (V , E) is ε−balanced if
θ(i, j) = 1 2 + ∂θ(i) − ∂θ(j) 2ε 1 In particular, ∂θ(i) ≤ ∂θ(j) − ε = ⇒ θ(i, j) = 0. Claim 1. There exists a unique ε−balanced allocation Θε. Claim 2. If [G, o]R ≡ [G ′, o′]R, then
SLIDE 142 Solution : relaxed load balancing
ε > 0 : perturbative parameter
- Definition. An allocation θ on G = (V , E) is ε−balanced if
θ(i, j) = 1 2 + ∂θ(i) − ∂θ(j) 2ε 1 In particular, ∂θ(i) ≤ ∂θ(j) − ε = ⇒ θ(i, j) = 0. Claim 1. There exists a unique ε−balanced allocation Θε. Claim 2. If [G, o]R ≡ [G ′, o′]R, then
- ∂Θε(G, o) − ∂Θε(G ′, o′)
- ≤ ∆
- 1 + 2ε
∆ −R .
SLIDE 143 Solution : relaxed load balancing
ε > 0 : perturbative parameter
- Definition. An allocation θ on G = (V , E) is ε−balanced if
θ(i, j) = 1 2 + ∂θ(i) − ∂θ(j) 2ε 1 In particular, ∂θ(i) ≤ ∂θ(j) − ε = ⇒ θ(i, j) = 0. Claim 1. There exists a unique ε−balanced allocation Θε. Claim 2. If [G, o]R ≡ [G ′, o′]R, then
- ∂Θε(G, o) − ∂Θε(G ′, o′)
- ≤ ∆
- 1 + 2ε
∆ −R .
- Corollary. Θε extends continuously to infinite graphs !
SLIDE 144
Proof outline
SLIDE 145 Proof outline
Assume Gn
loc.
− − − →
n→∞ L with
SLIDE 146 Proof outline
Assume Gn
loc.
− − − →
n→∞ L with
Consider a test function ψ: R → R (bounded, Lipschitz)
SLIDE 147 Proof outline
Assume Gn
loc.
− − − →
n→∞ L with
Consider a test function ψ: R → R (bounded, Lipschitz) 1 |Vn|
ψ (∂Θ(Gn, o))
???
− − − →
n→∞
(ψ ◦ ∂Θ)dL
SLIDE 148 Proof outline
Assume Gn
loc.
− − − →
n→∞ L with
Consider a test function ψ: R → R (bounded, Lipschitz) 1 |Vn|
ψ (∂Θ(Gn, o))
???
− − − →
n→∞
(ψ ◦ ∂Θ)dL 1 |Vn|
ψ (∂Θε(Gn, o)) − − − →
n→∞
(ψ ◦ ∂Θε) dL
SLIDE 149 Proof outline
Assume Gn
loc.
− − − →
n→∞ L with
Consider a test function ψ: R → R (bounded, Lipschitz) 1 |Vn|
ψ (∂Θ(Gn, o))
???
− − − →
n→∞
(ψ ◦ ∂Θ)dL
ε → 0 1 |Vn|
ψ (∂Θε(Gn, o)) − − − →
n→∞
(ψ ◦ ∂Θε) dL
SLIDE 150 Proof outline
Assume Gn
loc.
− − − →
n→∞ L with
Consider a test function ψ: R → R (bounded, Lipschitz) 1 |Vn|
ψ (∂Θ(Gn, o)) − − − →
n→∞
(ψ ◦ ∂Θ)dL
ε → 0 1 |Vn|
ψ (∂Θε(Gn, o)) − − − →
n→∞
(ψ ◦ ∂Θε) dL
SLIDE 151
Conclusion
SLIDE 152
Conclusion
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry of the graph.
SLIDE 153
Conclusion
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry of the graph.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L)
SLIDE 154
Conclusion
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry of the graph.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
SLIDE 155
Conclusion
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry of the graph.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
◮ Analytic implication: Φ admits a limit along most sparse
graph sequences. The distributional self-similarity of L may sometimes even allow for an explicit determination of Φ(L).
SLIDE 156
Conclusion
◮ In the sparse regime, many important graph parameters Φ are
essentially determined by the local geometry of the graph.
◮ This can be rigorously formalized by a continuity theorem:
Gn
loc.
− − − →
n→∞ L
= ⇒ Φ(Gn) − − − →
n→∞ Φ(L) ◮ Algorithmic implication: Φ is efficiently approximable via
local distributed algorithms, independently of network size.
◮ Analytic implication: Φ admits a limit along most sparse
graph sequences. The distributional self-similarity of L may sometimes even allow for an explicit determination of Φ(L).
◮ Many examples: spanning trees, spectrum and rank,
matching polynomial, Ising models, dense subgraphs...
SLIDE 157
Thank you !