
SLIDE 1
Table of contents
137
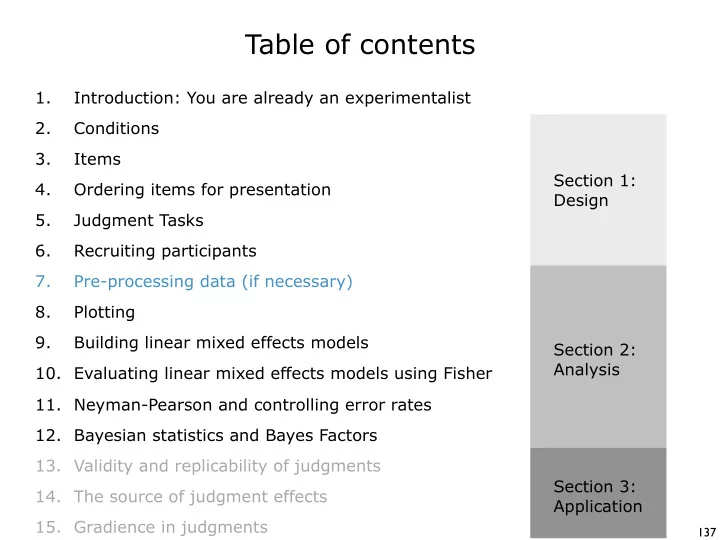
Table of contents 1. Introduction: You are already an - - PowerPoint PPT Presentation
Table of contents 1. Introduction: You are already an experimentalist 2. Conditions 3. Items Section 1: 4. Ordering items for presentation Design 5. Judgment Tasks 6. Recruiting participants 7. Pre-processing data (if necessary) 8.
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179