
SLIDE 1
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 1/10
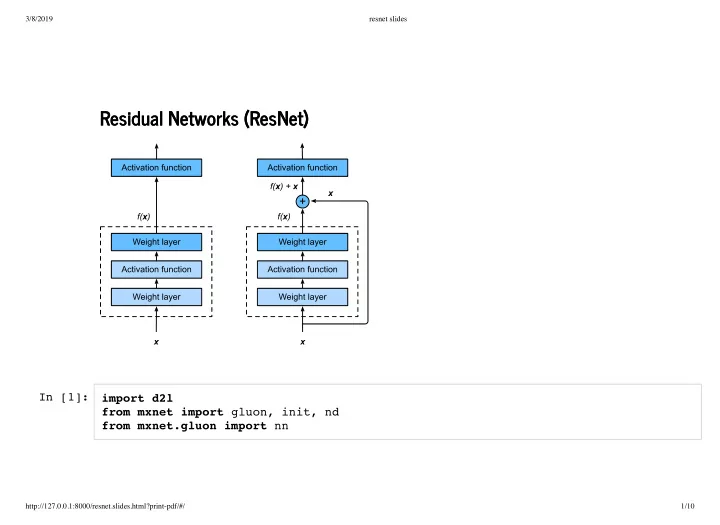
Residual Networks (ResNet) Residual Networks (ResNet) In [1]: - - PowerPoint PPT Presentation
3/8/2019 resnet slides Residual Networks (ResNet) Residual Networks (ResNet) In [1]: import d2l from mxnet import gluon, init, nd from mxnet.gluon import nn http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 1/10 3/8/2019 resnet slides
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 1/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 2/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 3/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 4/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 5/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 6/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 7/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 8/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 9/10
3/8/2019 resnet slides http://127.0.0.1:8000/resnet.slides.html?print-pdf/#/ 10/10