
SLIDE 1
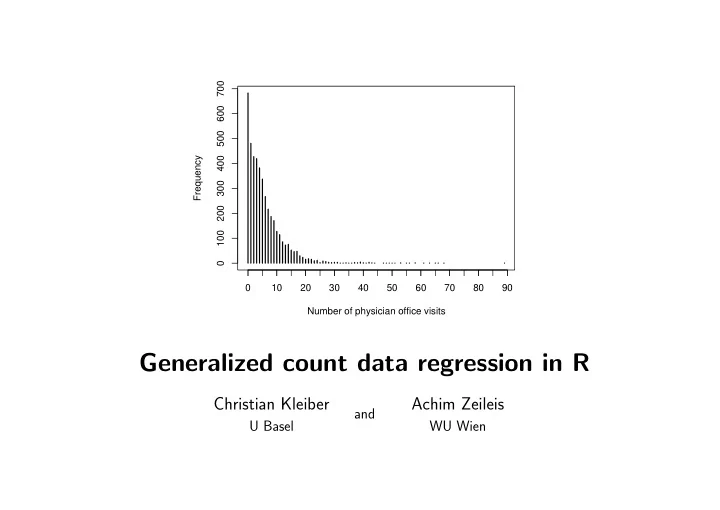
Number of physician office visits Frequency 100 200 300 400 500 600 700 10 20 30 40 50 60 70 80 90
Generalized count data regression in R Christian Kleiber Achim - - PowerPoint PPT Presentation
700 600 500 Frequency 400 300 200 100 0 0 10 20 30 40 50 60 70 80 90 Number of physician office visits Generalized count data regression in R Christian Kleiber Achim Zeileis and U Basel WU Wien Outline Introduction
Number of physician office visits Frequency 100 200 300 400 500 600 700 10 20 30 40 50 60 70 80 90
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
i β through which µi = E(yi|xi) depends on vectors xi of
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
i β),
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
fcount(y;x,β) 1−fcount(0;x,β)
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
i
C Kleiber
U Basel
i
i γ).
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel
C Kleiber
U Basel