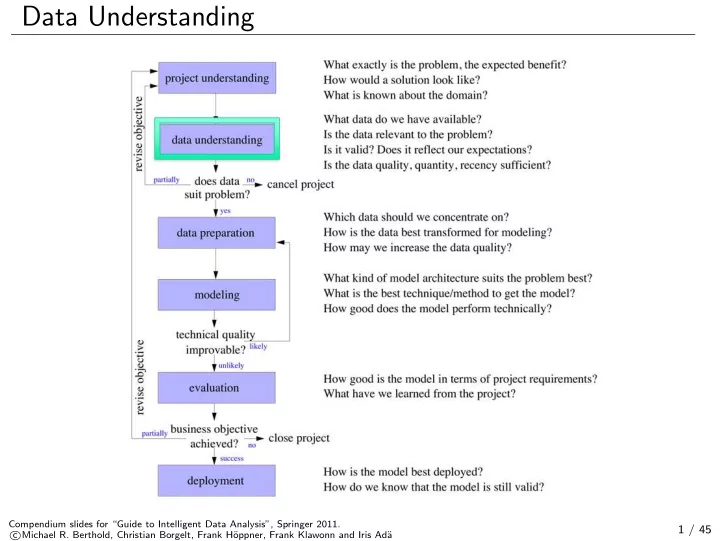
SLIDE 11 Histograms: Number of bins
–3 –2 –1 1 2 3 4 5 6 0.05 0.1 0.15 0.2
attribute value probability density
–3 –2 –1 1 2 3 4 5 6 7 50 100 150 200 250 300 350
attribute value frequency
–3 –2 –1 1 2 3 4 5 6 7 20 40 60 80 100 120
attribute value frequency
–3 –2 –1 1 2 3 4 5 6 7 5 10 15
attribute value frequency
Three histograms with 5, 17 and 200 bins for a sample from the same bimodal distribution.
Compendium slides for “Guide to Intelligent Data Analysis”, Springer 2011. c Michael R. Berthold, Christian Borgelt, Frank H¨
- ppner, Frank Klawonn and Iris Ad¨
a
11 / 45