
SLIDE 1
1 ¡
Ac%ve ¡learning ¡
Labels ¡are ¡expensive ¡(need ¡to ¡ask ¡expert) ¡ Want ¡to ¡minimize ¡the ¡number ¡of ¡labels ¡
+ –
- o
- +
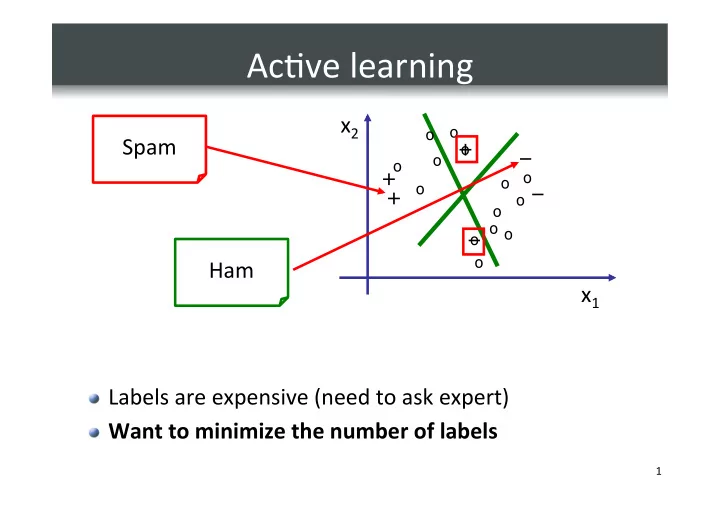
Ac%ve learning x 2 o o Spam + o o o + o o o + - - PowerPoint PPT Presentation
Ac%ve learning x 2 o o Spam + o o o + o o o + o o o o o o Ham x 1 Labels are expensive (need to ask expert) Want to minimize the number
1 ¡
Labels ¡are ¡expensive ¡(need ¡to ¡ask ¡expert) ¡ Want ¡to ¡minimize ¡the ¡number ¡of ¡labels ¡
Example: ¡Learning ¡linear ¡separators ¡in ¡1D ¡ For ¡now, ¡assume ¡data ¡is ¡noise ¡free ¡
2 ¡
3 ¡
Pool-‑based ¡ac%ve ¡learning ¡
Obtain ¡large ¡pool ¡of ¡unlabeled ¡data ¡ Selec%vely ¡request ¡a ¡few ¡labels, ¡un%l ¡we ¡can ¡infer ¡all ¡
Resul%ng ¡classifier ¡“as ¡good” ¡as ¡that ¡obtained ¡from ¡
Reduc%on ¡in ¡labels ¡
In ¡some ¡cases, ¡exponen%al ¡reduc%on ¡possible! ¡ In ¡other ¡cases, ¡may ¡need ¡to ¡request ¡almost ¡all ¡labels ¡
4 ¡
5 ¡
Given ¡pool ¡of ¡n ¡unlabeled ¡examples ¡ Repeat ¡un%l ¡we ¡can ¡infer ¡all ¡remaining ¡labels: ¡
Assign ¡each ¡unlabeled ¡data ¡an ¡“uncertainty ¡score” ¡ Greedily ¡pick ¡the ¡most ¡uncertain ¡example ¡and ¡request ¡label ¡
One ¡of ¡the ¡most ¡popular ¡heuris%cs! ¡
6 ¡
¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡
7 ¡
8 ¡
[Grauman ¡et ¡al] ¡
9 ¡
[Grauman ¡et ¡al] ¡
For ¡i ¡= ¡1:max_labels ¡
For ¡j ¡= ¡1:n ¡
Calculate ¡uncertainty ¡U(j) ¡score ¡of ¡example ¡j ¡
Pick ¡most ¡uncertain ¡example ¡ Retrain ¡SVM ¡
Complexity ¡to ¡pick ¡m ¡labels? ¡
10 ¡
11 ¡
) 1 ( + t
) 1 (
1
+ t
) 1 (
2
+ t
) (t
) (
1
t
) (
2
t
) 1 (
3
+ t
1 k
[Jain, Vijayanarasimhan & Grauman, NIPS 2010]
12 ¡
Unlabeled ¡ data ¡ Labeled ¡ data ¡ Current ¡Category ¡ Model ¡ Selected ¡ examples ¡
111.. ¡ 101.. ¡ 110.. ¡
Hashtable ¡
Hash ¡func%on ¡ Hash ¡func%on ¡
[Grauman ¡et ¡al] ¡
13 ¡
1
[Jain, ¡Vijayanarasimhan ¡& ¡Grauman, ¡NIPS ¡2010] ¡
14 ¡
= ¡More ¡likely ¡to ¡collide ¡ = ¡Unlikely ¡to ¡collide ¡
Less ¡likely ¡to ¡split ¡ + ¡Highly ¡likely ¡to ¡split ¡ Less ¡likely ¡to ¡split ¡ + ¡Less ¡likely ¡to ¡split ¡
[Grauman ¡et ¡al] ¡
15 ¡
= ¡More ¡likely ¡to ¡collide ¡ = ¡Unlikely ¡to ¡collide ¡
Less ¡likely ¡to ¡split ¡ + ¡Highly ¡likely ¡to ¡split ¡ Less ¡likely ¡to ¡split ¡ + ¡Less ¡likely ¡to ¡split ¡
[Grauman ¡et ¡al] ¡
, ¡
[Grauman ¡et ¡al] ¡
[Jain, Vijayanarasimhan & Grauman, NIPS 2010].
[Grauman ¡et ¡al] ¡
Hash all unlabeled data into table Active selection loop:
Hash current hyperplane as query Retrieve unlabeled data points with which it collides Request labels for them Update hyperplane
[Grauman ¡et ¡al] ¡
¡
[Grauman ¡et ¡al] ¡
[Grauman ¡et ¡al] ¡
Uncertainty ¡sampling: ¡Simple ¡heuris%c ¡for ¡ac%ve ¡
For ¡SVMs: ¡ ¡
pick ¡points ¡closest ¡to ¡decision ¡boundary ¡ Can ¡select ¡efficiently ¡using ¡LSH ¡
Can ¡get ¡significant ¡gains ¡in ¡labeling ¡cost, ¡even ¡for ¡
Now: ¡ ¡
Theory ¡of ¡ac%ve ¡learning ¡ Criteria ¡beyond ¡uncertainty ¡sampling ¡
21 ¡
22 ¡
Need ¡to ¡capture ¡how ¡much ¡“informa%on” ¡we ¡gain ¡about ¡
Version ¡space: ¡ ¡
Idea: ¡ ¡
23 ¡
24 ¡
[Tong ¡& ¡Koller] ¡
25 ¡
[Tong ¡& ¡Koller] ¡
26 ¡
[Tong ¡& ¡Koller] ¡
27 ¡
[Tong ¡& ¡Koller] ¡
Uncertainty ¡sampling ¡picks ¡data ¡point ¡closest ¡to ¡
28 ¡
Uncertainty ¡sampling ¡picks ¡data ¡point ¡closest ¡to ¡
29 ¡
Ideally: ¡Wish ¡to ¡select ¡example ¡that ¡splits ¡the ¡version ¡
In ¡general, ¡halving ¡may ¡not ¡be ¡possible ¡ ¡
How ¡do ¡we ¡quan%fy ¡how ¡“balanced” ¡a ¡split ¡is? ¡
30 ¡
Version ¡space ¡for ¡data ¡set ¡ ¡ Suppose ¡we’re ¡also ¡given ¡an ¡unlabeled ¡pool ¡ ¡ Relevant ¡version ¡space: ¡ ¡
31 ¡
b V(D; U) = {h : U → {+1, −1} : ∃w ∈ V(D)∀x ∈ U sign(wT x) = h(y)}
Start ¡with ¡D ¡= ¡{} ¡ While ¡
¡For ¡each ¡unlabeled ¡example ¡x ¡in ¡U ¡compute ¡
Pick ¡example ¡x ¡where ¡ ¡
32 ¡
33 ¡
Ideally: ¡Wish ¡to ¡select ¡example ¡that ¡splits ¡the ¡version ¡
In ¡general, ¡halving ¡may ¡not ¡be ¡possible ¡ ¡
Generalized ¡binary ¡search ¡ Compe%%ve ¡with ¡op%mal ¡ac%ve ¡learning ¡scheme ¡ ¡
Size ¡of ¡the ¡(relevant) ¡version ¡space ¡ ¡
Need ¡approxima%on! ¡
34 ¡
Uncertainty ¡sampling ¡picks ¡data ¡point ¡closest ¡to ¡
35 ¡
36 ¡
Suggests ¡looking ¡at ¡the ¡margins ¡of ¡the ¡resul%ng ¡SVMs ¡
37 ¡
Key ¡idea: ¡look ¡at ¡how ¡labels ¡affect ¡resul%ng ¡classifier ¡ Suppose ¡we’re ¡considering ¡data ¡point ¡i ¡ For ¡each ¡possible ¡label ¡{+,-‑} ¡calculate ¡resul%ng ¡SVMs, ¡
Define ¡informa%veness ¡score ¡of ¡i ¡depending ¡on ¡how ¡
Max-‑min ¡margin: ¡ ¡ Ra%o ¡margin: ¡
38 ¡
39 ¡
40 ¡
[Tong ¡& ¡Koller] ¡
Max-‑min ¡margin ¡and ¡ra%o ¡margin ¡more ¡expensive ¡
Need ¡to ¡train ¡an ¡SVM ¡for ¡each ¡data ¡point, ¡for ¡each ¡label!! ¡
Prac%cal ¡tricks: ¡
Only ¡score ¡and ¡pick ¡from ¡small ¡random ¡subsample ¡of ¡data ¡ Only ¡use ¡“fancy” ¡criterion ¡for ¡the ¡first ¡10 ¡examples, ¡then ¡
Occasionally ¡pick ¡points ¡uniformly ¡at ¡random ¡
41 ¡
42 ¡
So ¡far, ¡we ¡have ¡assumed ¡that ¡labels ¡are ¡exact ¡ In ¡prac%ce, ¡there ¡is ¡always ¡noise. ¡How ¡should ¡we ¡deal ¡
Prac%ce: ¡
Can ¡use ¡same ¡algorithms ¡(simply ¡use ¡SVM ¡with ¡slack ¡variables) ¡
Theory: ¡
Analysis ¡much ¡harder ¡ Modified ¡version ¡of ¡generalized ¡binary ¡search ¡s%ll ¡works ¡if ¡
If ¡noise ¡is ¡correlated ¡need ¡new ¡criterion ¡[Golovin, ¡Krause, ¡Ray, ¡
43 ¡
Pool-‑based ¡ac%ve ¡learning ¡ Different ¡selec%on ¡strategies ¡
Uncertainty ¡sampling: ¡Efficient, ¡but ¡can ¡fail ¡ Informa%ve ¡sampling: ¡Expensive, ¡but ¡can ¡effec%vely ¡reduce ¡
Computa%onal ¡tricks ¡
Locality ¡sensi%ve ¡hashing ¡to ¡speed ¡up ¡uncertainty ¡sampling ¡ Hybrid ¡selec%on ¡criteria ¡
44 ¡