SLIDE 1
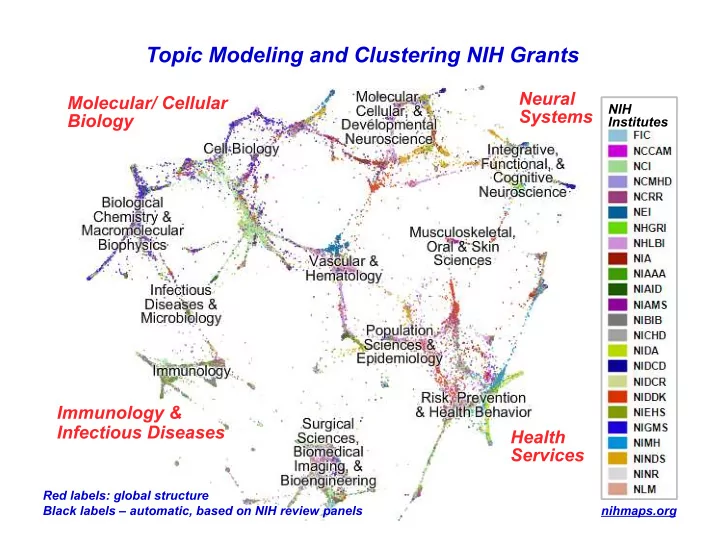
Health Services Molecular/ Cellular Biology Neural Systems
Topic Modeling and Clustering NIH Grants
Immunology & Infectious Diseases
NIH Institutes
Red labels: global structure Black labels – automatic, based on NIH review panels nihmaps.org
SLIDE 2 Two Complementary Analytic Systems
Map-like Clusters
- Based on overall textual similarity
between grants
- Represent groupings of grants that
share a common thematic focus Automated Topics
- Groupings of words determined by
statistical analysis
- Represent shared categories – each
document consists of multiple topics
SLIDE 3
Background – NINDS Effort
SLIDE 4
- Based on language in documents – not keywords
– Native categories that are latent in the text – captures shared discourses – Groups of words rather than individual concepts – Context sensitive – accommodates diverse word meanings
- Documents assigned to multiple categories
– Documents treated as mixtures of topics
- Quantitative information on textual content
Topic allocation (proportion of words assigned to a topic) serves as a proxy for document relevance. Topic allocations are used for:
– Topic-based queries – user sets document threshold – Ranking for lists of retrieved documents – Topic proportions for retrieved document sets – Measure similarity between documents
Methods 1: Topic Modeling using LDA
SLIDE 5 Methods 2: Graph Based Clustering using DrL
– Nodes are attracted by similarity and repelled by areas of density – Highly scalable – Documents clustered based on lexical (topic and word) similarities
– Local: thematically coherent clusters with striking face-validity – Intermediate: clusters linked in a lattice - links are formed by documents with “between cluster” focus – Global: compelling organization based on language rather than NIH bureaucratic structure
- Interactive visual framework
– Recognize patterns in the data that otherwise would be obscure
SLIDE 6
SLIDE 7
Uploaded NSF Cognitive/Neuro Grants
Document Upload for Analysis against NIH Awards
SLIDE 8 NIH Study Sections
CVP - Central Visual Processing COG - Cognitive Neuroscience CP - Cognition and Perception LCOM - Language and Communication
NIH Program Directors
STEINMETZ, MICHAEL (NEI) BABCOCK, DEBRA (NINDS) VOGEL, MICHAEL (NIMH) ROSSI, ANDREW (NIMH)
NIH Top Similar to Uploaded Documents
Document Upload for Analysis against NIH Awards
SLIDE 9 Acknowledgements
- Original Inspiration and Development
Gully Burns (USC) Dave Newman (UC Irvine) Bruce Herr (Indiana) Katy Borner (Indiana)
Dave Newman (UC Irvine) Hanna Wallach (UMass) David Mimno (UMass) Andrew McCallum (UMass)
- Map and User Interface Design
Bruce Herr (Chalklabs) Gavin LaRowe (Chalklabs) Nathan Skiba (Chalklabs)
Many many people
SLIDE 10
Machine Learned Topics vs. NIH Study Sections
SLIDE 11
Machine Learned Topics vs. NIH Study Sections
SLIDE 12
73 27 14 6 123 18 3 2
Somatosensory & Chemosensory Systems Study Section
Subset Inside the Bounded Region Subset Outside the Bounded Region
Topics and clusters reveal research categories within Study Sections that are highly relevant to NIH Institutes
SLIDE 13 Machine Learned Topics vs. NIH RCDC Categories NIH RCDC Category: Sleep Research
- Combined query with individual topics reveals finer grained
research categories
- Once again, clearly relevant to NIH Institutes
SLIDE 14
196 (29%) 183 (27%)
NIH RCDC Category: Sleep Research
Two prominent clusters account for ~56% of the awards
SLIDE 15 Research Trend Analysis
changed over this time period
- Biggest “hit”: microRNA
- Co-occurring topics
2007 vs. 2009: Cellular/molecular biology vs. Complex physiology, Cancer biomarkers
SLIDE 16
Topic Representation Within the Database
Co-occurring and similar topics give surrounding concept space Associated document metadata determined post-hoc by mutual information scoring Associated title words and document phrases give extra lexical information Full grant list ranked by topic allocation allows determination of threshold for tagging accuracy
SLIDE 17
A: Good Topic
Topic Evaluation
B: Poor Topic
Word Co-Occurrence Score Topic Size (% total) Good (94.3%) Intermediate (3.4%) Poor (2.3%)
A B
SLIDE 18 Title: Structure and Regulation of the GPCR- G Protein Interactions in the Visual System
Photo- receptor Cells Protein Structure
b: c:
a: b: c:
Initiating Grant: Topic Mix of Initiating Grant: GPCR Signaling
a:
100 Most Similar Grants:
Grant Similarity vs. Layout Proximity
Similar grants are not necessarily proximal
- n the graph, instead they are clustered
Clusters correspond to the topics of the initiating grant
SLIDE 19 Document Retrieval Performance
Graph Proximity vs. Document Similarity Values
(n = 100-300), graph performance is comparable to similarity scores, which are the inputs
- This is # grants in all the
previous examples
documents are clustered Most Similar Closest on Graph
SLIDE 20 Document 2 – “play” > Topic 82 > [literature] Document 1 – “play” > Topic 77 > [music] Document 3 – “play” > Topic 166 > [game]
Topics that include the word “play”
Topic word assignments are sensitive to the contexts in which the words occur
Each instance of a word is assigned to a specific topic, depending on assignments of other words in the document. Topics are mixtures of words, each with an associated probability, which are learned from word co-
- ccurrence within documents.
Documents that contain the word “play” Topic 77 Topic 82 Topic 166