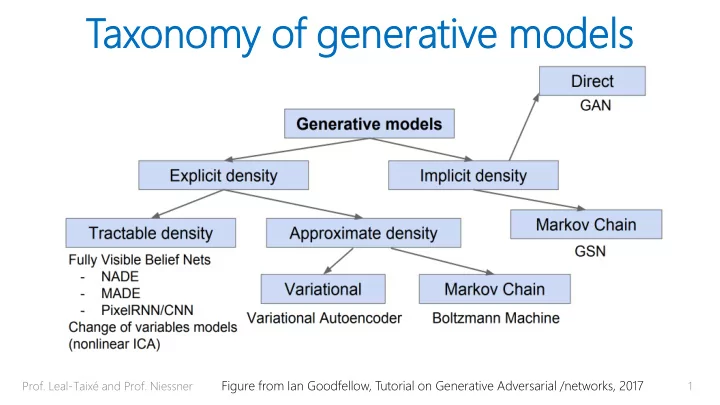

SLIDE 1
Tax axono
- nomy
my of f ge generativ erative e mo models dels
- Prof. Leal-Taixé and Prof. Niessner
1
Figure from Ian Goodfellow, Tutorial on Generative Adversarial /networks, 2017