
SLIDE 1
Sensitivity Analysis and Active Subspace Construction for Surrogate Models Employed for Bayesian Inference
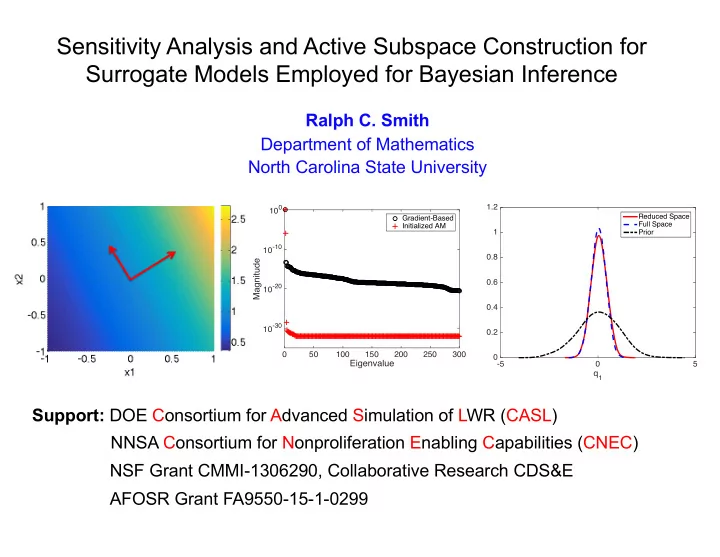
Ralph C. Smith Department of Mathematics North Carolina State University Support: DOE Consortium for Advanced Simulation of LWR (CASL) NSF Grant CMMI-1306290, Collaborative Research CDS&E NNSA Consortium for Nonproliferation Enabling Capabilities (CNEC)
q1
- 5
5 0.2 0.4 0.6 0.8 1 1.2
Reduced Space Full Space Prior
Eigenvalue
50 100 150 200 250 300
Magnitude
10-30 10-20 10-10 100
Gradient-Based Initialized AM