
SLIDE 1
Introduction to Information Retrieval
http://informationretrieval.org IIR 2: The term vocabulary and postings lists Hinrich Sch¨ utze Institute for Natural Language Processing, Universit¨ at Stuttgart 2008.04.28 1 / 60Overview
1 Recap 2 The term vocabulary 3 Skip pointers 4 Phrase queries 2 / 60Outline
1 Recap 2 The term vocabulary 3 Skip pointers 4 Phrase queries 3 / 60Inverted index
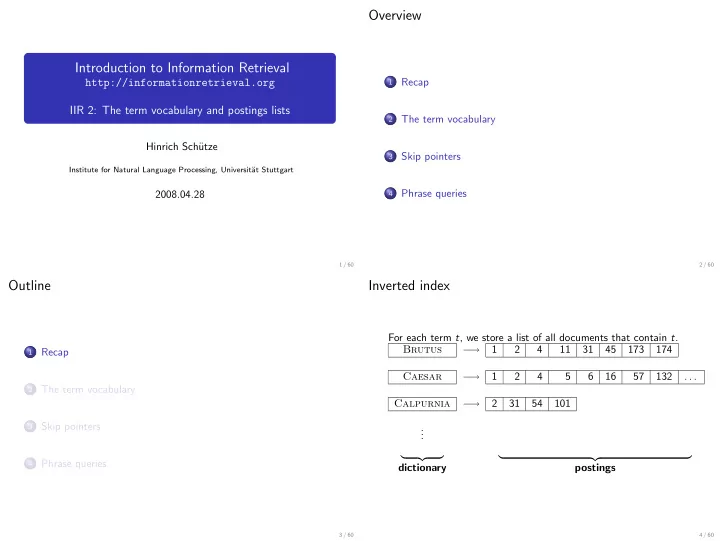
For each term t, we store a list of all documents that contain t. Brutus − → 1 2 4 11 31 45 173 174 Caesar − → 1 2 4 5 6 16 57 132 . . . Calpurnia − → 2 31 54 101 . . .- dictionary