
SLIDE 1
Foundations of Artificial Intelligence
- 8. Machine Learning
Learning from Observations Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller
Albert-Ludwigs-Universit¨ at Freiburg
Juli 1, 2011
Learning
What is learning? An agent learns when it improves its performance w.r.t. a specific task with experience. → E.g., game programs Why learn? → Engineering, philosophy, cognitive science → Data Mining (discovery of new knowledge through data analysis) No intelligence without learning!
(University of Freiburg) Foundations of AI Juli 1, 2011 2 / 37
Contents
1
The learning agent
2
Types of learning
3
Decision trees
(University of Freiburg) Foundations of AI Juli 1, 2011 3 / 37
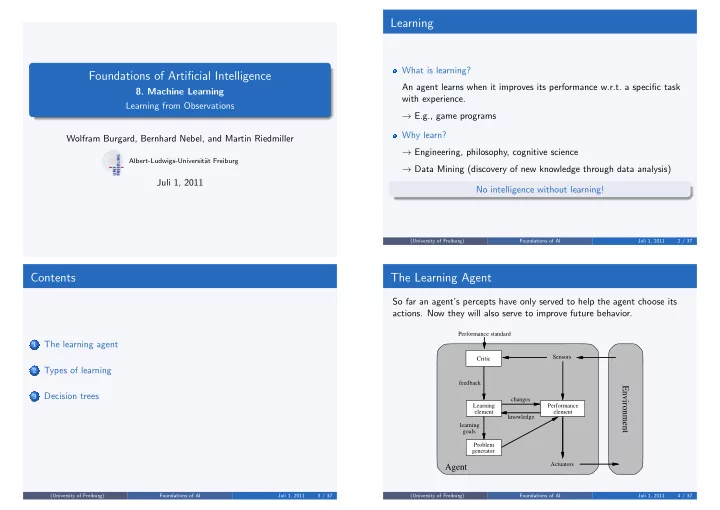
The Learning Agent
So far an agent’s percepts have only served to help the agent choose its
- actions. Now they will also serve to improve future behavior.
Performance standard
Agent Environment
Sensors Performance element changes knowledge learning goals Problem generator feedback Learning element Critic Actuators
- (University of Freiburg)
Foundations of AI Juli 1, 2011 4 / 37