
SLIDE 1
‹#›
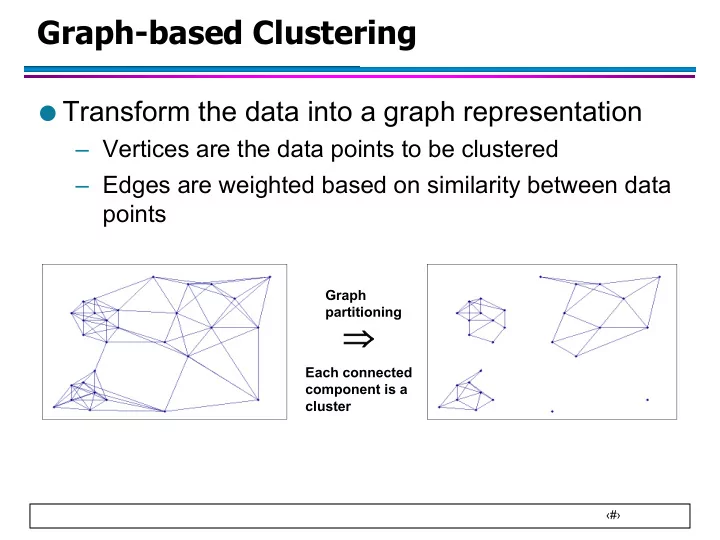
Graph-based Clustering
- Transform the data into a graph representation
– Vertices are the data points to be clustered – Edges are weighted based on similarity between data points
Þ
Graph partitioning Each connected component is a cluster